Эта статья посвящена созданию модели данных, которая красиво ложилась бы на SQL и содержала в себе «правильное» ООП наследование. Надо сказать, что эта задача возникала у меня в разное время на разных проектах, и решалась она там тоже по-разному. Названия подходов взяты из сложившейся на соответствующих проектах терминологии.
Подход №1: По умолчанию
Самый простой способ заключается в том, чтобы полностью довериться механизму Entity Framework. Если создать пустой проект, а в нём – пустую модель данных, в которую добавить классы, на основании которых будет сгенерирована база данных, получится примерно следующее (инструмент — Visual Studio 2012):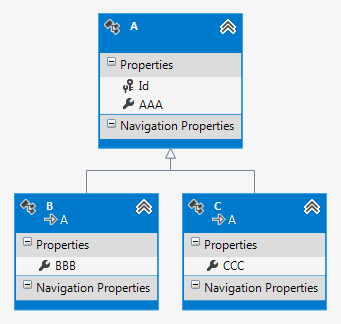
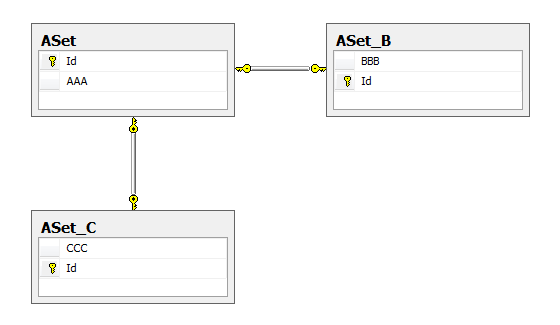
Что ж, весьма оптимально, надо признать. Единственное, что смущает – это специфичные имена таблиц. Вот соответствующие скрипты для создания таблиц базы данных, полученные с помощью инструмента «Tasks/Generate scripts»:
CREATE TABLE [dbo].[ASet](
[Id] [int] IDENTITY(1,1) NOT NULL,
[AAA] [nvarchar](max) NOT NULL,
CONSTRAINT [PK_ASet] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
CREATE TABLE [dbo].[ASet_C](
[CCC] [nvarchar](max) NOT NULL,
[Id] [int] NOT NULL,
CONSTRAINT [PK_ASet_C] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
CREATE TABLE [dbo].[ASet_B](
[BBB] [nvarchar](max) NOT NULL,
[Id] [int] NOT NULL,
CONSTRAINT [PK_ASet_B] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
ALTER TABLE [dbo].[ASet_C] WITH CHECK ADD CONSTRAINT [FK_C_inherits_A] FOREIGN KEY([Id]) REFERENCES [dbo].[ASet] ([Id]) ON DELETE CASCADE
ALTER TABLE [dbo].[ASet_C] CHECK CONSTRAINT [FK_C_inherits_A]
ALTER TABLE [dbo].[ASet_B] WITH CHECK ADD CONSTRAINT [FK_B_inherits_A] FOREIGN KEY([Id]) REFERENCES [dbo].[ASet] ([Id]) ON DELETE CASCADE
ALTER TABLE [dbo].[ASet_B] CHECK CONSTRAINT [FK_B_inherits_A]
Смущают в этом подходе только имена таблиц.
Подход №2: Classification
Этот способ показывает, как делали раньше, когда небо было выше, а динозавры ещё писали программы на фортране. (Признаться, мне казалось, что в эпоху MS SQL Server 2005 и Visual Studio 2008 я получил именно такой результат с помощью «Generate Database from Model» из Entity Framework.)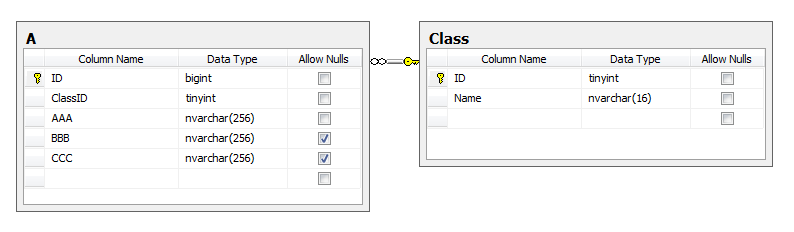
Скрипты и database-first модель данных я опущу, так как они достаточно тривиальны. Минус приведённого подхода очевиден. Как только у классов B и C вырастает количество столбцов, не относящихся к предку A (особенно, если это поля char[]-типа постоянного размера), то место на диске, занимаемое таблицей, начинает резко расти при том, что доля полезной информации в этом кладбище байт пропорционально сокращается. Нормализация? – не, не слышали… К сожалению, в силу исторических причин (например, для поддержания обратной совместимости), такие схемы всё ещё встречаются в крупных enterprise-проектах, разработка которых ведётся на протяжении нескольких лет. Но в новых разработках так поступать явно не стоит. Пожалуйста…
Подход №3: Polymophic View
Создание view над таблицами, имеющими одинаковые поля, в коде может быть представлено с помощью интерфейса (представление view в коде) и реализующих его классов (представление таблицы в коде). Плюсов два. Первый состоит в том, нет таких проблем с неэффективным использованием дискового пространства, как в предыдущем подходе. Второй: можно использовать индексы и прочие штучки, ускоряющие выгрузку данных из базы. Минус – код для SQL-запросов на выборку и добавление данных писать придётся ручками. Вот, например, код выборки из такого view:
CREATE VIEW [A] AS SELECT * FROM (
SELECT [AID] AS ID, 1 AS [ClassID], [AAA] FROM [B]
UNION ALL
SELECT [AID] AS ID, 2 AS [ClassID], [AAA] FROM [C]
) Q
Очевидно, что поля таблиц B и C такой запрос получить не позволяет. Можно в него засунуть ещё и получение этих самых столбцов BBB и CCC, в результате чего ответ с кучей NULL-ов станет сильно похож на вариант Classification:
CREATE VIEW [A] AS SELECT * FROM (
SELECT [AID] AS ID, 1 AS [ClassID], [AAA], [BBB], NULL AS [CCC] FROM [B]
UNION ALL
SELECT [AID] AS ID, 2 AS [ClassID], [AAA] , NULL AS [BBB], [CCC] FROM [C]
) Q
Подход №4: Иерархические таблицы
Лично моё двухколёсное педально-рулевое решение заключается в создании отдельной таблицы для каждого класса-потомка, которые будут связаны с таблицей класса-родителя связями «1-к-1».
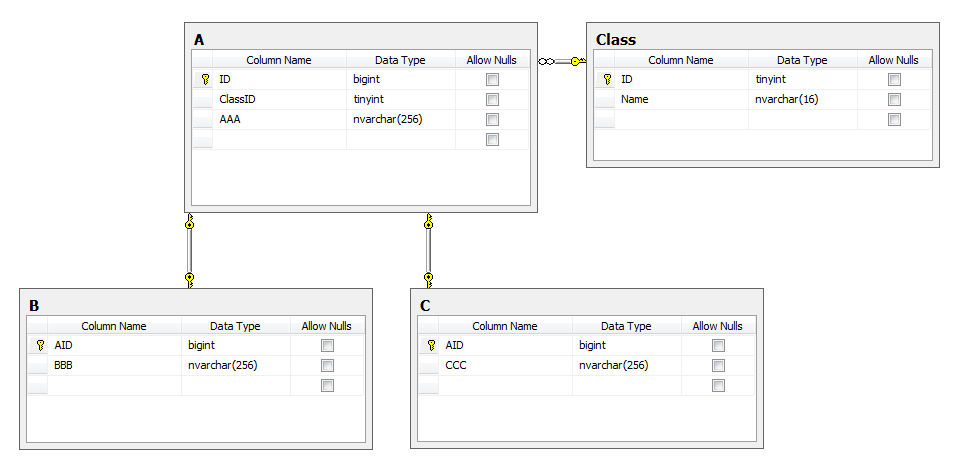
Очевидно, что поддерживать целостность такой схемы придётся с помощью триггеров, которые будут вырезать записи из родительской таблицы при удалении соответствующих детей (и наоборот) и контролировать добавление/редактирование записей, чтобы ребёнку из таблицы X соответствовала запись родителя с типом «X», а не, например, «Y».
Так как я люблю использовать в своих проектах Entity Framework, для создания соответствующей структуры классов мне приходится прилагать дополнительные усилия. Параллельно с классами из папки «Entity», куда попадает database-first сгенерированный код, имеется ещё папка «BusinessLogic», классы в которой имеют уже более внятные связи. Вот как делается код преобразования «Entity Framework → Business Logic» и «Business Logic → Entity Framework».
- Создаём интерфейс IA в папке «Entity».
public interface IA { A A { get; } EntityReference<A> AReference { get; } } - Наследуем от него автосгенерированные классы B и C, лежащие в той же папке.
- Создаём enum с названием типа AClassEnum, в который переписываем фактически все строки из таблицы Class.
- В папке «BusinessLogic» создаём классы abstract A, B:A и C:A. (Кстати, делать A абстрактным не обязательно – просто у меня так получалось в силу требований.)
- Пишем примерно следующее:
public abstract class A { public long ID { get; set; } public abstract ClassEnum Class { get; } public string AAA { get; set; } protected A() { } protected A(Entity.IA a) { if (!a.AReference.IsLoaded) { a.AReference.Load(MergeOption.NoTracking ); } if (a.A.ClassID != (byte) Class) { throw new Exception("Class type {0} instead of {1}!", a.A.Class, (ClassEnum) a.A.ClassID)); } ID = a.A.ID; } public Entity. A CreateA() { return new Entity.A { ClassID = (byte) Class, }; } } public class B : A { public string BBB { get; set; } public override ClassEnum Class { get { return ClassEnum.B; } } public B() : base() { } public B(Entity.B b) : base(b) { BBB = b.BBB; } public override Entity.B ToEntity() { return new Entity.B { A = CreateA(), BBB = BBB, }; } }
- … подходом по умолчанию – более красивые имена таблиц
- … таблицей «классификации» – меньший объём данных
- … вьюшкой – всё красиво импортируется в Entity Framework
Комментариев нет:
Отправить комментарий