28.04.17. 2017 год стал значимым событием для PG Day — мы преобразовали наше мероприятие в крупнейшую конференцию, посвященную базам данных.
Мы не изменяем своим традициям и готовим насыщенную и интересную программу, посвященную Посгресу. Тем не менее, общение с коллегами и обратная связь от участников дают однозначно понять, что огромное количество специалистов занимается эксплуатацией нескольких систем для хранения данных, вынужденно или же по собственному решению. Мы не хотим лишать коллег возможности пообщаться друг с другом, обменяться опытом и найти способы решить свои проблемы. Именно поэтому, в 2017 году PG Day делится на 5 параллельных потоков по различным направлениям: PostgreSQL, MySQL, Oracle, MS SQL Server, NoSQL решения и другие бесплатные и коммерческие СУБД.
Не смотря на то, что радикальные изменения в структуре ПГ Дня начались только в этом году, интерес к нашему мероприятию от колег по цеху стал появляться уже значительно раньше. На одном из прошлых PG Day Андрей Рынкевич представил интереснейший доклад От Oracle к PostgreSQL – путь длиною в 4 года, основанный на опыте миграции в компании Phorm, расшифровку которого мы рады представить читателям Хабра.
Доклад «От Oracle к PostgreSQL – путь длиною в 4 года” о самом большом вызове в нашем проекте, который должен завершиться в ближайший месяц с установкой продуктов, полностью работающих на PostgreSQL, на “продакшн”.

В самом начале у нас был Oracle и практически никакой пользовательской активности. В таких условиях все равно, какие технологии вы используете. Неважно, как хорошо вы пишите запросы – все работает идеально. Но на помощь вам приходят аналитики.
Так появился особый вид статистики, ключи в которой даже при наших слабых нагрузках полностью забили диск под завязку: это было около 5 ТБ. Статистику мы, конечно, отключили, но первый раз стали задумываться о дополнительной базе данных для расширения. Нагрузка росла, но наши возможности по оптимизации ограничивались лицензией Oracle. Текущая лицензия позволяет использовать только 4 ядра, при таком ограничении мы не можем даже standby использовать для запросов, у нас нет партиционирования – на таком паровозе далеко не уедешь. Поэтому мы начали смотреть варианты для расширения.

В начале мы рассмотрели возможности Oracle. Текущая лицензия нам стоила 15000 фунтов в год (support плюс upgrade на новые версии). Снятие лицензионных ограничений на процессоры и документы для партиционирования добавляло к этой сумме довольно значительный вклад, поэтому мы не стали идти этим путем, так как денег особо не было.
Первым решением, на которое мы взглянули, был MySQL. На тот момент в наших проектах уже использовался MySQL, но, поговорив с людьми, мы поняли, что он показал себя довольно проблемным и с ограниченной функциональностью. Поэтому совсем чуть-чуть взглянули на NoSQL решения. Разработчиков под NoSQL у нас тогда не было, и это показалось нам очень кардинальным изменением, поэтому мы это тоже отложили в сторону.
Наиболее устраивающим нас решением был Greenplum – это MPP БД, построенная на базе PostgreSQL. Конечно, единственный минус это то, что она тоже была платная, но суммы уже не такие как у Oracle, поэтому мы решили остановиться на PostgreSQL с целью дальше мигрировать на Greenplum. По плану такая миграция не должна была быть слишком трудной.

Для начала мы купили два хоста: master + standby (24 ядра, 128 GB оперативки), построили трехтерабайтный (3 TB) RAID10 – это не SSD диски, потому что SSD в тот момент стоили очень дорого. И задумались, что же нам дальше делать.
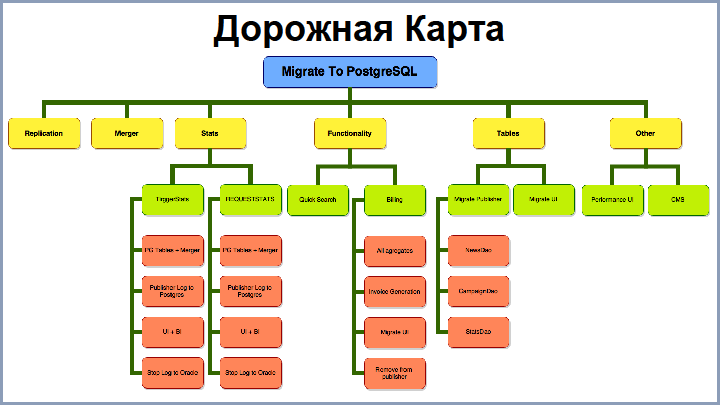
Признаюсь, в самом начале у нас не было четкого детального понимания всех шагов миграции. В какой-то момент нам все-таки пришлось нарисовать дорожную карту, как нам двигаться. На экране вы видите сильно урезанный вариант этой дорожной карты. Из этапов можно выделить следующие:
Дальше – последовательно о каждом этапе.
В самом начале мы уже понимали, что у нас не будет возможности мигрировать в один присест, поэтому мы решили начать со статистики. И образовался такой момент, что какая-то статистика частично находится на PostgreSQL, а остальное – на Oracle (в основном, сущности). Проблема в том, что отчеты требуют и того, и другого. Вопрос: как же мы будем строить отчеты?
Вариант на Oracle мы отмели сразу, потому что у нас все-таки возможности там ограничены. Возможно, настроить сервис приложения, выкачивать сущности из Oracle, а статистику – из PostgreSQL, как-то соединяя и фильтруя. Такое приложение выполняет работу за базу данных. Этот подход нам показался очень сложным, поэтому дальше мы реализовали три подхода, которые используем в разных степенях.
Первый вариант: выкачивать необходимые сущности из Oracle с помощью DBI link при запросе на отчет в PostgreSQL, – этот подход рабочий и хорошо применим для небольших выборок, поскольку, когда нужно большие данные перекачивать с большим количеством сущностей, всё резко замедляется, плюс, оптимизация таких запросов очень сложна. Такой подход актуален, когда нужна актуальность сущностей: выходишь на страничку “редактировать”, добавляешь новый элемент и, уже при сохранении, его сразу нужно отобразить с новой статистикой.
Следующий вариант – перекачка полностью всех сущностей из Oracle в PostgreSQL, периодическая перекачка всех сущностей. Такой подход мы тоже используем, но дело в том, что количество сущностей занимает у нас около 100 ГБ, поэтому актуальность сущности в постгресе отстает. Но этот вариант хорошо работает, когда нужно обрабатывать большие отчеты, которые не требуют актуальности данных. Но, зная наших операторов, которые прибегают к нам через полчаса, как только какой-то вид статистики начинает отставать, мы решили реализовать потоковую репликацию: сущность при обновлении на Oracle практически сразу попадает в Postgres.
Для решения этого вопроса были рассмотрены следующие варианты:
WisdomForce Database Sync – это продукт коммерческий, который существовал в то время. Он вполне нас устраивал и скорость давал примерно 5 000 обновлений в секунду, но, в тот момент когда мы уже решили его использовать, его перекупила другая компания, и проект исчез с рынка, поэтому пришлось нам разбираться и строить решения самим.
Первый вариант, который был рассмотрен, это Oracle DataChange Capture. Это джавовские процессы, которые запускаются в базе данных Oracle. Они умеют отлавливать изменения табличек и запихивать их в очереди. К сожалению, скорость этого решения у нас потерялась в истории, но она была не очень высока.
Первый же вариант репликации был построен на Materialized View Log-ах – это специальные таблички Oracle, которые хранят все изменения мастер-таблички и служат для быстрого пересчета в Materialized View.
Это решение оказалось довольно простым в реализации и давало скорость около 500 обновлений в секунду, но продукт рос и этого оказалось мало. Дальше мы перешли на специальную оракловую технологию Stream, которая служит для репликации данных из Oracle в другие источники. Текущая скорость также позволяет перекачивать и обновлять сущности со скоростью 5000 обновлений в секунду (в пределе можно было довести до 50 000), при этом средняя задержка занимает до 30 секунд. Причем, что интересно, если даже вы обновили одну запись в Oracle, то она попадает в Stream не сразу, а с некоторой задержкой, потому что есть некоторая латентность во всех этих процессах.
Также у Oracle есть продолжение стрим-технологии – XStreams, который позволяет получать более высокие результаты, но это решение у них платное, поэтому мы его протестировали, но использовать не стали.

Схема репликации довольно простая. Теперь на Oracle поднимаются процессы, которые читают redo-логи – это аналог WAL-файлов в PostgreSQL. Все таблички, которые нужно реплицировать, записываются в отдельную табличку “Replication data”. С помощью промежуточного софта, на каждую табличку навешиваются процессы-обработчики redo-логов. В итоге, на выходе мы получаем данные, которые тоже складываются нашу табличку “Replication Data”.
На стороне же PostgreSQL, у нас построено приложение / утилита репликации на Java – она читает эти данные из Replication Data и записывает в PostgreSQL. Плюс ее в том, что при наличии возможности считывать и записывать данные потранзакционно, нарушения целостности нет.
Что касается скорости 5000 в секунду – в основном, узким звеном в этом месте является утилита репликации. Стрим-процессы, как я говорил, позволяют держать до 50 000 сортировок / обновлений. Для ускорения утилиты, мы разбили ее на 3 потока:

Stream процессы позволяют не только реплицировать данные, но и DDL. Мы вначале ринулись решать эту задачу. Благо, система сложная, и хотелось максимально уменьшить все ручные дергания, но это оказалось непросто, потому что сам язык DDL многообразен. Плюс, есть момент неоднозначности трансляции DDL с Oracle в PostgreSQL. Бывало так, что часто у нас на продакшене выскакивали неучтенные варианты этого DDL. В итоге мы решили, что проще нам будет проще пересоздавать их в постгресе и перезаливать данные. В итоге мы оставили одну инструкцию, которая мы поддерживаем – это TRUNCATE.

Скорость 5000 обновлений в секунду, в большинстве случаев, приемлима, но есть один момент, когда всё-таки её не хватало. Это именно патчинг большого объема данных в Oracle. Так, бывали случаи, когда обновление затрагивало десятки гигабайт. Stream процессы достаточно тяжеловесны, потому прогонять все эти объёмы через них довольно накладно для сервера. Поэтому мы придумали такую схемку.
Если разработчик баз данных понимает, что его патч затронет большое количество изменений, он в системе патчиков выставляет определенный флаг, что нужно остановить репликацию. Применяя этот патч, система патчинга останавливала stream процессы, делала свои дела с табличками и в самом конце записывала в нашу табличку replication маркер о том, что патчинг закончился и флаг, что нужно инициализировать таблички. Дальше система патчинга приступала к постгресу. Она дожидалась этот последний маркер, записанный в Oracle, уже на Postgres, который проходил через репликацию. Он всегда приходил последний. Система смотрела на флаг и, если нужно пересоздавать таблички, она их пересоздавала и выкачивала все сущности из Oracle с помощью DBI link. И дальше делала патчинг самой системы. На этом с репликацией всё.

Следующий этап – загрузка данных в саму базу данных. По сути, у нас проект разбит на несколько: собственно, сама база данных; UI, который заливает в базу сущности и выдает отчёты; сервер логов, который ежедневно прокачивает через базу 150 GB, используя stored процедуры.
Поскольку разработчики баз данных не очень контролируют связку log-сервер – база данных, появляется много проблем. Например, статистика приходит из разных стран, в разное время и в разных объёмах, что периодически выдаёт скачки нагрузки. Понятно, что это влияет на всех пользователей. Следующая проблема, иногда неожиданная: log-сервер выдает слишком большие пачки данных. Опять же, обработка таких пачек занимает много ресурсов у сервера и влияет на все остальные процессы. К тому же, есть еще сложность в обработке провалившихся патчей для статистики.
Если что-то “зафейлилось”, эта статистика остаётся на log-сервере. Разработчику баз данных нужно каким-то образом туда попасть (а это не всегда возможно), преобразовать stored процедурой (в плане, вызвать, поправить, снова залить). Это довольно сложное решение. Поэтому на стороне постгреса мы немножко пошли другим путём, а именно заливаем файлы, т.е. сервер логов уже не вызывает stored процедуры, а выдает csv-файлы.

Есть программка Merger, которая по определенным правилам каждый вид статистики заливает в базу данных. Все “сфэйленные” файлики размещались на том же хосте, это решало все предыдущие проблемы, т.е. скачки нагрузки сказывались только на кол-ве необработанных файлов на диске. “Фэйленные” файлики всегда можно было найти, поправить тут же руками, положить обратно и загрузить. Также, большие пачки Merger разбивал на части, поэтому не было очень длинных транзакций.

Merger тоже прошёл несколько долгий путь.
Первый вариант был сделан на коленке и выглядит, как вот эта строчка зелёная. Это его решение. То есть, создавалась для каждого вида статистики “стейджинговая” табличка и процедура, которая эти таблички помещала в базу данных. Но этот вариант подходит не для всех решений, поэтому мы хотели прийти к чему-то более простому, более универсальному. Так у нас появился второй вариант.
На экране вы видите самое первое и самое простое правило по обработке статистики. Программа по имени файла понимала, какое правило нужно брать, этому же правилу соответствовала табличка в базе данных. Из этой таблички выбирались первичные ключи и уже по этим первичным ключам для каждой строки уже можно было понять, нужно делать INSERT или UPDATE.
Такими правилами описывается большинство видов статистики, но вариантов всё-таки множество. Поэтому синтаксис Merger всё растёт и растёт. Так, есть правила для INSERT, UPDATE, задание условий, когда нужно делать то или другое партиционирование, залитие всякими другими извращёнными способами. Но выделить, пожалуй, можно следующее. Бывает так, что статистика приходит раньше, чем сущности, в PostgreSQL. Это бывает, например, когда сама репликация “упала” или не работала какое-то время.

Для решения этой проблемы мы тоже создали хитрую схемку. В Oracle существует табличка, HEART_BEAT называется, И job, который каждые 30 секунд в неё вставляет timestamp. Эта табличка реплицируется в базу PostgreSQL, и Merger уже может понимать, что требуется. Он смотрит последний пришедший heartbeat и обрабатывает только те файлы, которые младше этого heartbeat’а, иначе у нас могут потеряться некоторые данные. Понятно, что если сущности нету, а она уже есть в статистике, то при мердже она исчезнет.

Имея репликацию и Merger, мы могли перейти к переносу статистики. На слайде вы можете видеть немного изменённую и урезанную версию этого процесса. Из этапов можно выделить следующие:
Почему-то у нас была боязнь перенести сразу всё остальное. Поэтому мы на каждом этапе пытались как-то держаться с возможностью вернуться назад, если что-то пойдёт не так. Если двойное логирование сохранялось на продакшене какое-то время, то мы начинали переводить как UI, так и отчёты.
Здесь мы тоже реализовали нашу боязнь перехода, и поэтому в системе могли существовать сразу два одинаковых отчёта, один из которых работал на Oracle, а другой на PostgreSQL. Это оказалось достаточно удобно как для разработчиков, так и для тестировщиков: всегда можно было запустить одинаковые запросы, увидеть результаты и наглядно сравнить их, решить найденные проблемы.

Чем больше статистики оказывалось в PostgreSQL, тем чаще возникали новые кейсы. Так, например, по статистике, находящейся в PostgreSQL, нам в какой-то момент понадобилось обновление сущностей уже в Oracle. Например, при переходе некоторых пороговых значений, нужно было поменять статус. В данному случае на стороне постгреса мы заводили какой-то job, который максимально агрегировал нужную статистику и запихивал в Oracle через dbi link. Там – уже через stored процедуру либо в отдельную табличку, которая обрабатывалась соответствующим job’ом в Oracle. После чего данные, статусы и сущности менялись в Oracle и через репликацию приходили в PostgreSQL.

Догадываетесь что это? Это набор сущностей. Я загнал в Modeler все сущности, и он построил все связи между ними. Как вы видите, сетка довольно плотная, не всё даже в экран влезло. Поэтому такой же трюк со статистикой: перенести всё по частям у нас не получилось, потому что связи довольно плотные. К тому же в UI у нас работает ORM-система, и разрывать связи там довольно сложно. По сути, приходится реализовывать двухфазный commit в разные базы данных. Запустить два варианта в одну и ту же ORM-ку тоже было проблемным для модели. Поэтому мы решили всю миграцию сущностей отложить на последний рывок, при этом предварительно подготовив все необходимые моменты.
Для одной из табличек нам всё-таки пришлось реализовать перенос, разорвать связи, это заняло довольно долгое время. Причина в том, что эта табличка очень большая и она интенсивно менялась. Было накладно для начальной инициализации в постгресе (необходимость перекачивать все сущности) и для процесса репликации.
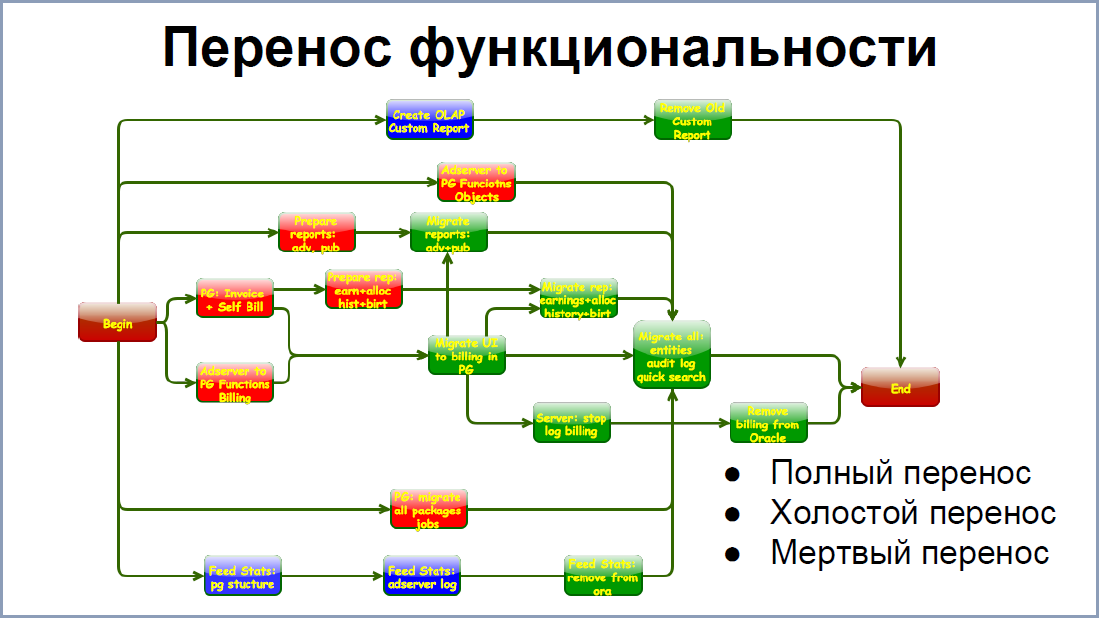
С переносом функциональности было немного попроще. На экране вы видите некоторую взаимосвязь этапов перехода какой-то части системы из Oracle на PostgreSQL. Связей уже, конечно, поменьше, но каждый квадратик состоит из квадратиков, который имеет свои связи. Поэтому, чтобы облегчить последний рывок, мы максимально упростили всё, что можем. Выделить можно три варианта.
Полный перенос функциональности, когда мы её полностью удаляли из Oracle и запускали на постгресе. В некоторых случаях это было возможно.
В большинстве случаев мы переносили функциональность и запускали ее вхолостую. Например, биллинг у нас проработал в таком режиме около года, позволив нам найти много performance проблем и ряд критических багов. Но результаты такого биллинга, понятное дело, выкидывались в мусорку.
Мертвый перенос – это перенос stored процедур, переписывание их с Oracle на постгрeс. Эти процедуры могли даже не работать. И, зачастую, они и не работали, не вызывались. Но это нам позволило создать набор “болванок” к следующему шагу.

Собственно, подготовив всё, чтобы перейти к последнему рывку, мы сладили с этим последним рывком. По сути, мы перенесли все статистики, включили ту функциональность, что работала вхолостую и которая лежала мёртвым грузом. Сам релиз происходил с довольно большим “даунтаймом”, поскольку нужно перекачать довольно большое количество актуальных данных и по пунктам выполнить некоторые миграции. Интересно что, несмотря на то, что мы много всего сделали, мы обнаружили, что мы забыли перенести определённые модули, поэтому мы были вынуждены отложить релиз где-то на неделю. И даже после этого, где-то через неделю-две, мы нашли ещё один модуль, который не был мигрирован, и нам уже пришлось допиливать по-живому.

Итак, 4 года – это довольно большой срок. Чтобы понять, оправдана эта величина или нет, мы выписали ряд метрик, часть из которых вы видите на слайде. Наверное, каждый из вас ошибался в первоначальной оценке объема той или иной работы. Такую ошибку совершили и мы. Изначально наша оценка была год-полтора. И вот даже сейчас, когда всё завершилось, мало кто называет цифру более двух лет, потому что всё это слилось в непрерывный поток.
Как видите, база не очень большая, но и не то, чтобы очень маленькая. Если брать по коду, то, чтобы написать такое количество с 0, нужно писать около 80 строчек в день. Это не так чтобы и очень много даже для небольшой команды.
Самое большое время заняло исследование и сравнение различных вариантов решения. Из других моментов, которые не технические, можно выделить несколько. Как видите, в переносе было задействовано около 30 человек, которые работали в разных командах, разных местах. И координация вот такой сборной команды потребовала довольно продолжительное время.
Одним из моментов была потеря фокуса. Я долго думал, что это такое, пока не столкнулся с этим воочию. Дело в том, что мы действовали на опережение и у нас не было таких больших проблем на Oracle в большинстве случаев, поэтому все задачи на миграцию шли немного в фоне. И, поскольку сиюминутных задач было довольно много, это стратегическое направление немножко задвигалось на второй план. Были такие случаи, когда мы забывали про миграцию на неделю или на две.

Несмотря на то, что PostgreSQL — довольно классная БД и с каждым релизом она нам нравится всё больше и больше, всё-таки некоторых моментов нам не хватало во время миграции.
Джобы, в Oracle они существуют в самой базе и было непривычно выходить за рамки базы, запускать какой-то crontab. К тому же нужно всё это мониторить, что оно всё запускается и выполняется хорошо.
Resource management: иногда хорошо разделить ресурсы между процессами, например, между пользовательскими запросами и статистикой.
Самая крутая штука, которая есть в Oracle, на мой взгляд, поскольку спасала меня несколько раз, это flashback. Это возможность восстановить какую-то версию за какой-то непродолжительный промежуток времени. Что-то подобное мы думаем сейчас думаем реализовать на постгресе, поскольку были моменты, когда приходилось восстанавливать большие куски сущностей из-за инцидентов.
Также OEM (Oracle Enterprise Management) – это такое web-приложение. Когда у нас те или иные проблемы, DBA залазит в эту OEM, видит все активности, какие там есть. Может пройти по историям, посмотреть, что же происходило, сравнить взаимодействие различных аспектов и проделать всякие свои админские штуки. В PostgreSQL, понятно, у DBA мастерство на кончиках пальчиков, поэтому все запросы он может выдать с такой же скоростью, как и через это приложение, но удобство при этом страдает для людей, которые не являются DBA. Поэтому свой вариант OEM мы всё-таки написали, важно было сохранение всей истории обращения по таблицам и запросам. В итоге, мы могли зайти и посмотреть, что же там тормозило, увидеть всякие взаимосвязи и сделать изменения в нашем коде.

Greenplum мы всё-таки не купили, кризис, но объемы у нас растут, поэтому мы сталкиваемся с теми же проблемами, которые у нас были уже Oracle, на PostgreSQL, но уже в более крупных масштабах. Так, первая из проблем, с которой мы столкнулись, это ограничение по диску. В какой-то момент, нам даже пришлось сделать операцию un-raid на нескольких разделах. Превратив тем самым RAID-10 в RAID-5, кажется.
Самая главная проблема этой операции в том, что при этом теряются данные, сохраненные на этих разделах, поэтому нам пришлось на диске поиграть в пятнашки, чтобы всё там уместилось. По запросам у нас тоже проблемы, мы утыкаемся на некоторых в ограничении в обработке, вплоть до того, что часть функциональности нам даже приходится отключать. Причём объемные какие-то статистики, которые требуют много места и обработки, мы даже из постгреса вынесли в отдельное место и развиваем всё это направление особым способом, потому что чем дальше, тем всё хуже.
Новую версию смотрели? Смотрели-смотрели, но мы основную статистику, если кратко, перенесли в Hadoop. На хадупе у нас стоит Impala, такая колоночная, по сути, база данных, которая отвечает за наши данные. И у нас даже стратегически задача вынести все объёмные статистики, которые не нужны ни для биллинга, ни для работы сиюминутных jobs, в Hadoop кластер и, если нам что-то понадобится, то когда-то возвращать.
Так, у нас операторы любят смотреть почасовую статистику. Объем ключей в главной таблице событий очень большой и это накладно для сервера, поэтому часовую статистику мы уже вынесли в Hadoop.

Тематическое расширение PG Day'17 усилило интерес наших слушателей и докладчиков к тематике миграций с одного хранилища данных на другое. Вопросы миграции будут рассматриваться практически в каждой секции, так что вопросов не останется ни у кого! Специально для вас мы готовимся представить несколько интересных докладов.
Василий Созыкин из Яндекс.Деньги поведает про дао миграции нагруженного сервиса с Oracle на PotgreSQL, захватывающая история о том, как специалисты Яндекса мигрировали поистине огромную базу без „даунтайма“. Александр Коротков из компании Postgres Professional в своем докладе „Наш ответ Uber'у“ произведет разбор нашумевшей истории о переезде популярного Такси-сервиса с PostgreSQL обратно на MySQL. Кристина Кучерова из Distillery расскажет, как они с коллегами пришли к решению о миграции OLTP части своей системы с MS SQL на PostgreSQL, и чем это для них обернулось.
Ну а четвертый, не менее интригующий доклад об онлайн-репликации данных в Greenplum из 25 СУБД под управлением Oracle для вас готовит Дмитрий Павлов, руководитель группы администрирования Date Warehouse в банке Тинькофф. Дмитрий уже не в первый раз выступает на PG Day. Его предыдущие доклады имели оглушительный успех и собирали до отказа набитые залы.
В самый последний момент, когда мы готовили этот выпуск к публикации и уже были готовы нажать кнопку „Опубликовать“, коллеги из НИИ „Восход“ подали заявку на доклад. Дмитрий Погибенко расскажет об успешной миграции базы данных государственной системы „Мир“ (более 10 Тб данных!) с DB2 на PostgreSQL с минимальным простоем.
Мы не изменяем своим традициям и готовим насыщенную и интересную программу, посвященную Посгресу. Тем не менее, общение с коллегами и обратная связь от участников дают однозначно понять, что огромное количество специалистов занимается эксплуатацией нескольких систем для хранения данных, вынужденно или же по собственному решению. Мы не хотим лишать коллег возможности пообщаться друг с другом, обменяться опытом и найти способы решить свои проблемы. Именно поэтому, в 2017 году PG Day делится на 5 параллельных потоков по различным направлениям: PostgreSQL, MySQL, Oracle, MS SQL Server, NoSQL решения и другие бесплатные и коммерческие СУБД.
Не смотря на то, что радикальные изменения в структуре ПГ Дня начались только в этом году, интерес к нашему мероприятию от колег по цеху стал появляться уже значительно раньше. На одном из прошлых PG Day Андрей Рынкевич представил интереснейший доклад От Oracle к PostgreSQL – путь длиною в 4 года, основанный на опыте миграции в компании Phorm, расшифровку которого мы рады представить читателям Хабра.
Доклад «От Oracle к PostgreSQL – путь длиною в 4 года” о самом большом вызове в нашем проекте, который должен завершиться в ближайший месяц с установкой продуктов, полностью работающих на PostgreSQL, на “продакшн”.
В самом начале у нас был Oracle и практически никакой пользовательской активности. В таких условиях все равно, какие технологии вы используете. Неважно, как хорошо вы пишите запросы – все работает идеально. Но на помощь вам приходят аналитики.
Так появился особый вид статистики, ключи в которой даже при наших слабых нагрузках полностью забили диск под завязку: это было около 5 ТБ. Статистику мы, конечно, отключили, но первый раз стали задумываться о дополнительной базе данных для расширения. Нагрузка росла, но наши возможности по оптимизации ограничивались лицензией Oracle. Текущая лицензия позволяет использовать только 4 ядра, при таком ограничении мы не можем даже standby использовать для запросов, у нас нет партиционирования – на таком паровозе далеко не уедешь. Поэтому мы начали смотреть варианты для расширения.
В начале мы рассмотрели возможности Oracle. Текущая лицензия нам стоила 15000 фунтов в год (support плюс upgrade на новые версии). Снятие лицензионных ограничений на процессоры и документы для партиционирования добавляло к этой сумме довольно значительный вклад, поэтому мы не стали идти этим путем, так как денег особо не было.
Первым решением, на которое мы взглянули, был MySQL. На тот момент в наших проектах уже использовался MySQL, но, поговорив с людьми, мы поняли, что он показал себя довольно проблемным и с ограниченной функциональностью. Поэтому совсем чуть-чуть взглянули на NoSQL решения. Разработчиков под NoSQL у нас тогда не было, и это показалось нам очень кардинальным изменением, поэтому мы это тоже отложили в сторону.
Наиболее устраивающим нас решением был Greenplum – это MPP БД, построенная на базе PostgreSQL. Конечно, единственный минус это то, что она тоже была платная, но суммы уже не такие как у Oracle, поэтому мы решили остановиться на PostgreSQL с целью дальше мигрировать на Greenplum. По плану такая миграция не должна была быть слишком трудной.
Для начала мы купили два хоста: master + standby (24 ядра, 128 GB оперативки), построили трехтерабайтный (3 TB) RAID10 – это не SSD диски, потому что SSD в тот момент стоили очень дорого. И задумались, что же нам дальше делать.
Признаюсь, в самом начале у нас не было четкого детального понимания всех шагов миграции. В какой-то момент нам все-таки пришлось нарисовать дорожную карту, как нам двигаться. На экране вы видите сильно урезанный вариант этой дорожной карты. Из этапов можно выделить следующие:
- репликация данных из базы Oracle в базу PostgreSQL;
- Merger – как способ заливки “сырых” блоков в саму БД;
- перенос статистики из Oracle в Postgres;
- перенос функциональности;
- перенос таблиц и сопутствующих проектов.
Дальше – последовательно о каждом этапе.
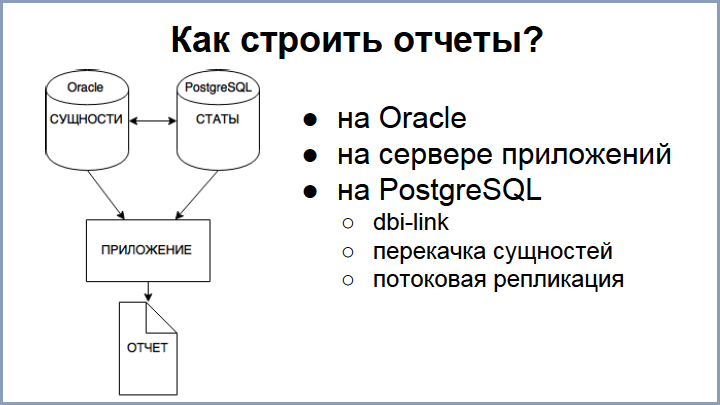
В самом начале мы уже понимали, что у нас не будет возможности мигрировать в один присест, поэтому мы решили начать со статистики. И образовался такой момент, что какая-то статистика частично находится на PostgreSQL, а остальное – на Oracle (в основном, сущности). Проблема в том, что отчеты требуют и того, и другого. Вопрос: как же мы будем строить отчеты?
Вариант на Oracle мы отмели сразу, потому что у нас все-таки возможности там ограничены. Возможно, настроить сервис приложения, выкачивать сущности из Oracle, а статистику – из PostgreSQL, как-то соединяя и фильтруя. Такое приложение выполняет работу за базу данных. Этот подход нам показался очень сложным, поэтому дальше мы реализовали три подхода, которые используем в разных степенях.
Первый вариант: выкачивать необходимые сущности из Oracle с помощью DBI link при запросе на отчет в PostgreSQL, – этот подход рабочий и хорошо применим для небольших выборок, поскольку, когда нужно большие данные перекачивать с большим количеством сущностей, всё резко замедляется, плюс, оптимизация таких запросов очень сложна. Такой подход актуален, когда нужна актуальность сущностей: выходишь на страничку “редактировать”, добавляешь новый элемент и, уже при сохранении, его сразу нужно отобразить с новой статистикой.
Следующий вариант – перекачка полностью всех сущностей из Oracle в PostgreSQL, периодическая перекачка всех сущностей. Такой подход мы тоже используем, но дело в том, что количество сущностей занимает у нас около 100 ГБ, поэтому актуальность сущности в постгресе отстает. Но этот вариант хорошо работает, когда нужно обрабатывать большие отчеты, которые не требуют актуальности данных. Но, зная наших операторов, которые прибегают к нам через полчаса, как только какой-то вид статистики начинает отставать, мы решили реализовать потоковую репликацию: сущность при обновлении на Oracle практически сразу попадает в Postgres.
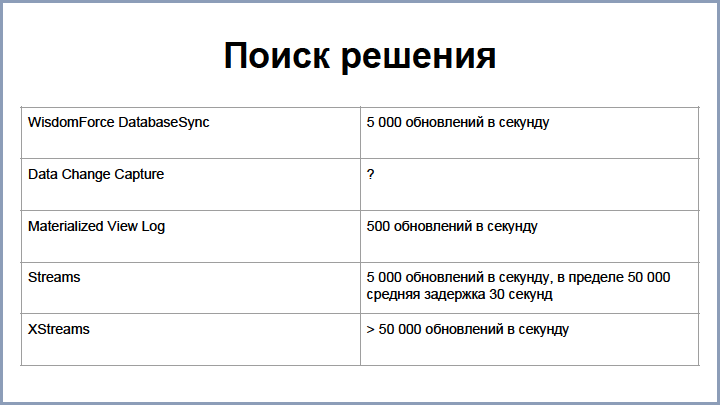
Для решения этого вопроса были рассмотрены следующие варианты:
WisdomForce Database Sync – это продукт коммерческий, который существовал в то время. Он вполне нас устраивал и скорость давал примерно 5 000 обновлений в секунду, но, в тот момент когда мы уже решили его использовать, его перекупила другая компания, и проект исчез с рынка, поэтому пришлось нам разбираться и строить решения самим.
Первый вариант, который был рассмотрен, это Oracle DataChange Capture. Это джавовские процессы, которые запускаются в базе данных Oracle. Они умеют отлавливать изменения табличек и запихивать их в очереди. К сожалению, скорость этого решения у нас потерялась в истории, но она была не очень высока.
Первый же вариант репликации был построен на Materialized View Log-ах – это специальные таблички Oracle, которые хранят все изменения мастер-таблички и служат для быстрого пересчета в Materialized View.
Это решение оказалось довольно простым в реализации и давало скорость около 500 обновлений в секунду, но продукт рос и этого оказалось мало. Дальше мы перешли на специальную оракловую технологию Stream, которая служит для репликации данных из Oracle в другие источники. Текущая скорость также позволяет перекачивать и обновлять сущности со скоростью 5000 обновлений в секунду (в пределе можно было довести до 50 000), при этом средняя задержка занимает до 30 секунд. Причем, что интересно, если даже вы обновили одну запись в Oracle, то она попадает в Stream не сразу, а с некоторой задержкой, потому что есть некоторая латентность во всех этих процессах.
Также у Oracle есть продолжение стрим-технологии – XStreams, который позволяет получать более высокие результаты, но это решение у них платное, поэтому мы его протестировали, но использовать не стали.
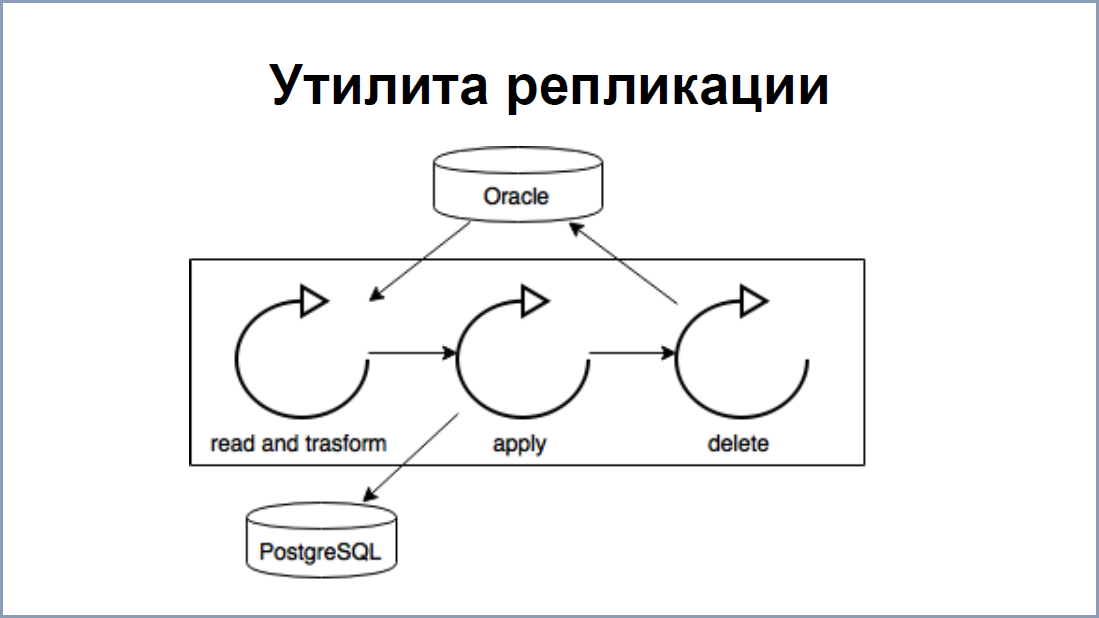
Схема репликации довольно простая. Теперь на Oracle поднимаются процессы, которые читают redo-логи – это аналог WAL-файлов в PostgreSQL. Все таблички, которые нужно реплицировать, записываются в отдельную табличку “Replication data”. С помощью промежуточного софта, на каждую табличку навешиваются процессы-обработчики redo-логов. В итоге, на выходе мы получаем данные, которые тоже складываются нашу табличку “Replication Data”.
На стороне же PostgreSQL, у нас построено приложение / утилита репликации на Java – она читает эти данные из Replication Data и записывает в PostgreSQL. Плюс ее в том, что при наличии возможности считывать и записывать данные потранзакционно, нарушения целостности нет.
Что касается скорости 5000 в секунду – в основном, узким звеном в этом месте является утилита репликации. Стрим-процессы, как я говорил, позволяют держать до 50 000 сортировок / обновлений. Для ускорения утилиты, мы разбили ее на 3 потока:
- Первый поток считывал данные из replication data и трансформировал в запросы, которые можно было применить уже на PostgreSQL.
- Второй применял эти изменения.
- Третий вычищал обработанные данные из таблички replication data.
Stream процессы позволяют не только реплицировать данные, но и DDL. Мы вначале ринулись решать эту задачу. Благо, система сложная, и хотелось максимально уменьшить все ручные дергания, но это оказалось непросто, потому что сам язык DDL многообразен. Плюс, есть момент неоднозначности трансляции DDL с Oracle в PostgreSQL. Бывало так, что часто у нас на продакшене выскакивали неучтенные варианты этого DDL. В итоге мы решили, что проще нам будет проще пересоздавать их в постгресе и перезаливать данные. В итоге мы оставили одну инструкцию, которая мы поддерживаем – это TRUNCATE.
Скорость 5000 обновлений в секунду, в большинстве случаев, приемлима, но есть один момент, когда всё-таки её не хватало. Это именно патчинг большого объема данных в Oracle. Так, бывали случаи, когда обновление затрагивало десятки гигабайт. Stream процессы достаточно тяжеловесны, потому прогонять все эти объёмы через них довольно накладно для сервера. Поэтому мы придумали такую схемку.
Если разработчик баз данных понимает, что его патч затронет большое количество изменений, он в системе патчиков выставляет определенный флаг, что нужно остановить репликацию. Применяя этот патч, система патчинга останавливала stream процессы, делала свои дела с табличками и в самом конце записывала в нашу табличку replication маркер о том, что патчинг закончился и флаг, что нужно инициализировать таблички. Дальше система патчинга приступала к постгресу. Она дожидалась этот последний маркер, записанный в Oracle, уже на Postgres, который проходил через репликацию. Он всегда приходил последний. Система смотрела на флаг и, если нужно пересоздавать таблички, она их пересоздавала и выкачивала все сущности из Oracle с помощью DBI link. И дальше делала патчинг самой системы. На этом с репликацией всё.
Следующий этап – загрузка данных в саму базу данных. По сути, у нас проект разбит на несколько: собственно, сама база данных; UI, который заливает в базу сущности и выдает отчёты; сервер логов, который ежедневно прокачивает через базу 150 GB, используя stored процедуры.
Поскольку разработчики баз данных не очень контролируют связку log-сервер – база данных, появляется много проблем. Например, статистика приходит из разных стран, в разное время и в разных объёмах, что периодически выдаёт скачки нагрузки. Понятно, что это влияет на всех пользователей. Следующая проблема, иногда неожиданная: log-сервер выдает слишком большие пачки данных. Опять же, обработка таких пачек занимает много ресурсов у сервера и влияет на все остальные процессы. К тому же, есть еще сложность в обработке провалившихся патчей для статистики.
Если что-то “зафейлилось”, эта статистика остаётся на log-сервере. Разработчику баз данных нужно каким-то образом туда попасть (а это не всегда возможно), преобразовать stored процедурой (в плане, вызвать, поправить, снова залить). Это довольно сложное решение. Поэтому на стороне постгреса мы немножко пошли другим путём, а именно заливаем файлы, т.е. сервер логов уже не вызывает stored процедуры, а выдает csv-файлы.
Есть программка Merger, которая по определенным правилам каждый вид статистики заливает в базу данных. Все “сфэйленные” файлики размещались на том же хосте, это решало все предыдущие проблемы, т.е. скачки нагрузки сказывались только на кол-ве необработанных файлов на диске. “Фэйленные” файлики всегда можно было найти, поправить тут же руками, положить обратно и загрузить. Также, большие пачки Merger разбивал на части, поэтому не было очень длинных транзакций.
Merger тоже прошёл несколько долгий путь.
Первый вариант был сделан на коленке и выглядит, как вот эта строчка зелёная. Это его решение. То есть, создавалась для каждого вида статистики “стейджинговая” табличка и процедура, которая эти таблички помещала в базу данных. Но этот вариант подходит не для всех решений, поэтому мы хотели прийти к чему-то более простому, более универсальному. Так у нас появился второй вариант.
На экране вы видите самое первое и самое простое правило по обработке статистики. Программа по имени файла понимала, какое правило нужно брать, этому же правилу соответствовала табличка в базе данных. Из этой таблички выбирались первичные ключи и уже по этим первичным ключам для каждой строки уже можно было понять, нужно делать INSERT или UPDATE.
Такими правилами описывается большинство видов статистики, но вариантов всё-таки множество. Поэтому синтаксис Merger всё растёт и растёт. Так, есть правила для INSERT, UPDATE, задание условий, когда нужно делать то или другое партиционирование, залитие всякими другими извращёнными способами. Но выделить, пожалуй, можно следующее. Бывает так, что статистика приходит раньше, чем сущности, в PostgreSQL. Это бывает, например, когда сама репликация “упала” или не работала какое-то время.
Для решения этой проблемы мы тоже создали хитрую схемку. В Oracle существует табличка, HEART_BEAT называется, И job, который каждые 30 секунд в неё вставляет timestamp. Эта табличка реплицируется в базу PostgreSQL, и Merger уже может понимать, что требуется. Он смотрит последний пришедший heartbeat и обрабатывает только те файлы, которые младше этого heartbeat’а, иначе у нас могут потеряться некоторые данные. Понятно, что если сущности нету, а она уже есть в статистике, то при мердже она исчезнет.
Имея репликацию и Merger, мы могли перейти к переносу статистики. На слайде вы можете видеть немного изменённую и урезанную версию этого процесса. Из этапов можно выделить следующие:
- создание табличек и правил для Merger;
- перевод сервер логов на логирование как в Oracle, так и в PostgreSQL через csv файлы.
Почему-то у нас была боязнь перенести сразу всё остальное. Поэтому мы на каждом этапе пытались как-то держаться с возможностью вернуться назад, если что-то пойдёт не так. Если двойное логирование сохранялось на продакшене какое-то время, то мы начинали переводить как UI, так и отчёты.
Здесь мы тоже реализовали нашу боязнь перехода, и поэтому в системе могли существовать сразу два одинаковых отчёта, один из которых работал на Oracle, а другой на PostgreSQL. Это оказалось достаточно удобно как для разработчиков, так и для тестировщиков: всегда можно было запустить одинаковые запросы, увидеть результаты и наглядно сравнить их, решить найденные проблемы.
Чем больше статистики оказывалось в PostgreSQL, тем чаще возникали новые кейсы. Так, например, по статистике, находящейся в PostgreSQL, нам в какой-то момент понадобилось обновление сущностей уже в Oracle. Например, при переходе некоторых пороговых значений, нужно было поменять статус. В данному случае на стороне постгреса мы заводили какой-то job, который максимально агрегировал нужную статистику и запихивал в Oracle через dbi link. Там – уже через stored процедуру либо в отдельную табличку, которая обрабатывалась соответствующим job’ом в Oracle. После чего данные, статусы и сущности менялись в Oracle и через репликацию приходили в PostgreSQL.
Догадываетесь что это? Это набор сущностей. Я загнал в Modeler все сущности, и он построил все связи между ними. Как вы видите, сетка довольно плотная, не всё даже в экран влезло. Поэтому такой же трюк со статистикой: перенести всё по частям у нас не получилось, потому что связи довольно плотные. К тому же в UI у нас работает ORM-система, и разрывать связи там довольно сложно. По сути, приходится реализовывать двухфазный commit в разные базы данных. Запустить два варианта в одну и ту же ORM-ку тоже было проблемным для модели. Поэтому мы решили всю миграцию сущностей отложить на последний рывок, при этом предварительно подготовив все необходимые моменты.
Для одной из табличек нам всё-таки пришлось реализовать перенос, разорвать связи, это заняло довольно долгое время. Причина в том, что эта табличка очень большая и она интенсивно менялась. Было накладно для начальной инициализации в постгресе (необходимость перекачивать все сущности) и для процесса репликации.
С переносом функциональности было немного попроще. На экране вы видите некоторую взаимосвязь этапов перехода какой-то части системы из Oracle на PostgreSQL. Связей уже, конечно, поменьше, но каждый квадратик состоит из квадратиков, который имеет свои связи. Поэтому, чтобы облегчить последний рывок, мы максимально упростили всё, что можем. Выделить можно три варианта.
Полный перенос функциональности, когда мы её полностью удаляли из Oracle и запускали на постгресе. В некоторых случаях это было возможно.
В большинстве случаев мы переносили функциональность и запускали ее вхолостую. Например, биллинг у нас проработал в таком режиме около года, позволив нам найти много performance проблем и ряд критических багов. Но результаты такого биллинга, понятное дело, выкидывались в мусорку.
Мертвый перенос – это перенос stored процедур, переписывание их с Oracle на постгрeс. Эти процедуры могли даже не работать. И, зачастую, они и не работали, не вызывались. Но это нам позволило создать набор “болванок” к следующему шагу.
Собственно, подготовив всё, чтобы перейти к последнему рывку, мы сладили с этим последним рывком. По сути, мы перенесли все статистики, включили ту функциональность, что работала вхолостую и которая лежала мёртвым грузом. Сам релиз происходил с довольно большим “даунтаймом”, поскольку нужно перекачать довольно большое количество актуальных данных и по пунктам выполнить некоторые миграции. Интересно что, несмотря на то, что мы много всего сделали, мы обнаружили, что мы забыли перенести определённые модули, поэтому мы были вынуждены отложить релиз где-то на неделю. И даже после этого, где-то через неделю-две, мы нашли ещё один модуль, который не был мигрирован, и нам уже пришлось допиливать по-живому.
Итак, 4 года – это довольно большой срок. Чтобы понять, оправдана эта величина или нет, мы выписали ряд метрик, часть из которых вы видите на слайде. Наверное, каждый из вас ошибался в первоначальной оценке объема той или иной работы. Такую ошибку совершили и мы. Изначально наша оценка была год-полтора. И вот даже сейчас, когда всё завершилось, мало кто называет цифру более двух лет, потому что всё это слилось в непрерывный поток.
Как видите, база не очень большая, но и не то, чтобы очень маленькая. Если брать по коду, то, чтобы написать такое количество с 0, нужно писать около 80 строчек в день. Это не так чтобы и очень много даже для небольшой команды.
Самое большое время заняло исследование и сравнение различных вариантов решения. Из других моментов, которые не технические, можно выделить несколько. Как видите, в переносе было задействовано около 30 человек, которые работали в разных командах, разных местах. И координация вот такой сборной команды потребовала довольно продолжительное время.
Одним из моментов была потеря фокуса. Я долго думал, что это такое, пока не столкнулся с этим воочию. Дело в том, что мы действовали на опережение и у нас не было таких больших проблем на Oracle в большинстве случаев, поэтому все задачи на миграцию шли немного в фоне. И, поскольку сиюминутных задач было довольно много, это стратегическое направление немножко задвигалось на второй план. Были такие случаи, когда мы забывали про миграцию на неделю или на две.
Несмотря на то, что PostgreSQL — довольно классная БД и с каждым релизом она нам нравится всё больше и больше, всё-таки некоторых моментов нам не хватало во время миграции.
Джобы, в Oracle они существуют в самой базе и было непривычно выходить за рамки базы, запускать какой-то crontab. К тому же нужно всё это мониторить, что оно всё запускается и выполняется хорошо.
Resource management: иногда хорошо разделить ресурсы между процессами, например, между пользовательскими запросами и статистикой.
Самая крутая штука, которая есть в Oracle, на мой взгляд, поскольку спасала меня несколько раз, это flashback. Это возможность восстановить какую-то версию за какой-то непродолжительный промежуток времени. Что-то подобное мы думаем сейчас думаем реализовать на постгресе, поскольку были моменты, когда приходилось восстанавливать большие куски сущностей из-за инцидентов.
Также OEM (Oracle Enterprise Management) – это такое web-приложение. Когда у нас те или иные проблемы, DBA залазит в эту OEM, видит все активности, какие там есть. Может пройти по историям, посмотреть, что же происходило, сравнить взаимодействие различных аспектов и проделать всякие свои админские штуки. В PostgreSQL, понятно, у DBA мастерство на кончиках пальчиков, поэтому все запросы он может выдать с такой же скоростью, как и через это приложение, но удобство при этом страдает для людей, которые не являются DBA. Поэтому свой вариант OEM мы всё-таки написали, важно было сохранение всей истории обращения по таблицам и запросам. В итоге, мы могли зайти и посмотреть, что же там тормозило, увидеть всякие взаимосвязи и сделать изменения в нашем коде.
Greenplum мы всё-таки не купили, кризис, но объемы у нас растут, поэтому мы сталкиваемся с теми же проблемами, которые у нас были уже Oracle, на PostgreSQL, но уже в более крупных масштабах. Так, первая из проблем, с которой мы столкнулись, это ограничение по диску. В какой-то момент, нам даже пришлось сделать операцию un-raid на нескольких разделах. Превратив тем самым RAID-10 в RAID-5, кажется.
Самая главная проблема этой операции в том, что при этом теряются данные, сохраненные на этих разделах, поэтому нам пришлось на диске поиграть в пятнашки, чтобы всё там уместилось. По запросам у нас тоже проблемы, мы утыкаемся на некоторых в ограничении в обработке, вплоть до того, что часть функциональности нам даже приходится отключать. Причём объемные какие-то статистики, которые требуют много места и обработки, мы даже из постгреса вынесли в отдельное место и развиваем всё это направление особым способом, потому что чем дальше, тем всё хуже.
Новую версию смотрели? Смотрели-смотрели, но мы основную статистику, если кратко, перенесли в Hadoop. На хадупе у нас стоит Impala, такая колоночная, по сути, база данных, которая отвечает за наши данные. И у нас даже стратегически задача вынести все объёмные статистики, которые не нужны ни для биллинга, ни для работы сиюминутных jobs, в Hadoop кластер и, если нам что-то понадобится, то когда-то возвращать.
Так, у нас операторы любят смотреть почасовую статистику. Объем ключей в главной таблице событий очень большой и это накладно для сервера, поэтому часовую статистику мы уже вынесли в Hadoop.
Тематическое расширение PG Day'17 усилило интерес наших слушателей и докладчиков к тематике миграций с одного хранилища данных на другое. Вопросы миграции будут рассматриваться практически в каждой секции, так что вопросов не останется ни у кого! Специально для вас мы готовимся представить несколько интересных докладов.
Василий Созыкин из Яндекс.Деньги поведает про дао миграции нагруженного сервиса с Oracle на PotgreSQL, захватывающая история о том, как специалисты Яндекса мигрировали поистине огромную базу без „даунтайма“. Александр Коротков из компании Postgres Professional в своем докладе „Наш ответ Uber'у“ произведет разбор нашумевшей истории о переезде популярного Такси-сервиса с PostgreSQL обратно на MySQL. Кристина Кучерова из Distillery расскажет, как они с коллегами пришли к решению о миграции OLTP части своей системы с MS SQL на PostgreSQL, и чем это для них обернулось.
Ну а четвертый, не менее интригующий доклад об онлайн-репликации данных в Greenplum из 25 СУБД под управлением Oracle для вас готовит Дмитрий Павлов, руководитель группы администрирования Date Warehouse в банке Тинькофф. Дмитрий уже не в первый раз выступает на PG Day. Его предыдущие доклады имели оглушительный успех и собирали до отказа набитые залы.
В самый последний момент, когда мы готовили этот выпуск к публикации и уже были готовы нажать кнопку „Опубликовать“, коллеги из НИИ „Восход“ подали заявку на доклад. Дмитрий Погибенко расскажет об успешной миграции базы данных государственной системы „Мир“ (более 10 Тб данных!) с DB2 на PostgreSQL с минимальным простоем.
Смотри также:
- Курсоры в MySQL. Применение и синтаксис. Примеры. http://fetisovvs.blogspot.com/2016/10/mysql_13.html
- Представления (VIEW) в MySQL. http://fetisovvs.blogspot.com/2016/10/view-mysql.html
- Календарные функции в MySQL и MariaDB. http://fetisovvs.blogspot.com/2016/12/mysql-mariadb.html
- Как писать кривые запросы с неоптимальным планом и заставить задуматься СУБД. http://fetisovvs.blogspot.com/2017/02/blog-post_2.html
- Базовые различия при работе с базами данными MySQL и PostgreSQL Дилетантский обзор. http://fetisovvs.blogspot.com/2016/06/mysql-postgresql.html
- Сравнение производительности MariaDB 10.1 и MySQL 5.7. http://fetisovvs.blogspot.com/2015/10/mariadb-101-mysql-57.html
- MySQL и MongoDB — когда и что лучше использовать. http://fetisovvs.blogspot.com/2017/02/mysql-mongodb.html
- Балансировка MySQL. http://fetisovvs.blogspot.com/2015/08/mysql.html
- DbForge Studio for MySQL - удобный набор инструментов для профессиональной разработки и управления MySQL базы данных. http://fetisovvs.blogspot.com/2014/10/dbforge-studio-for-mysql-mysql.html
- Основы работы с DbForge Studio - инструментом для работы с MySQL. http://fetisovvs.blogspot.com/2014/11/dbforge-studio-mysql.html
- На пути к правильным SQL транзакциям. http://fetisovvs.blogspot.com/2015/06/sql.html
- Работа с PostgreSQL настройка и масштабирование (справочное пособие). http://fetisovvs.blogspot.com/2014/08/postgresql.html
- Электронная книга Инсталляция MySQL 5.5.24 http://fetisovvs.blogspot.com/2014/09/mysql-5524.html
- Зачем нужна денормализация баз данных, и когда ее использовать. http://fetisovvs.blogspot.com/2016/04/blog-post_10.html
- Как sql-запросом извлечь из базы данных информацию, которой там нет. http://fetisovvs.blogspot.com/2016/06/sql.html
- История СУБД Oracle — первой коммерчески успешной реляционной СУБД. http://fetisovvs.blogspot.com/2016/12/oracle.html
- NoSQL – коротко о главном. http://fetisovvs.blogspot.com/2017/01/nosql.htm
Комментариев нет:
Отправить комментарий