04.03.17. Это — расшифровка доклада с Highload++ 2016.
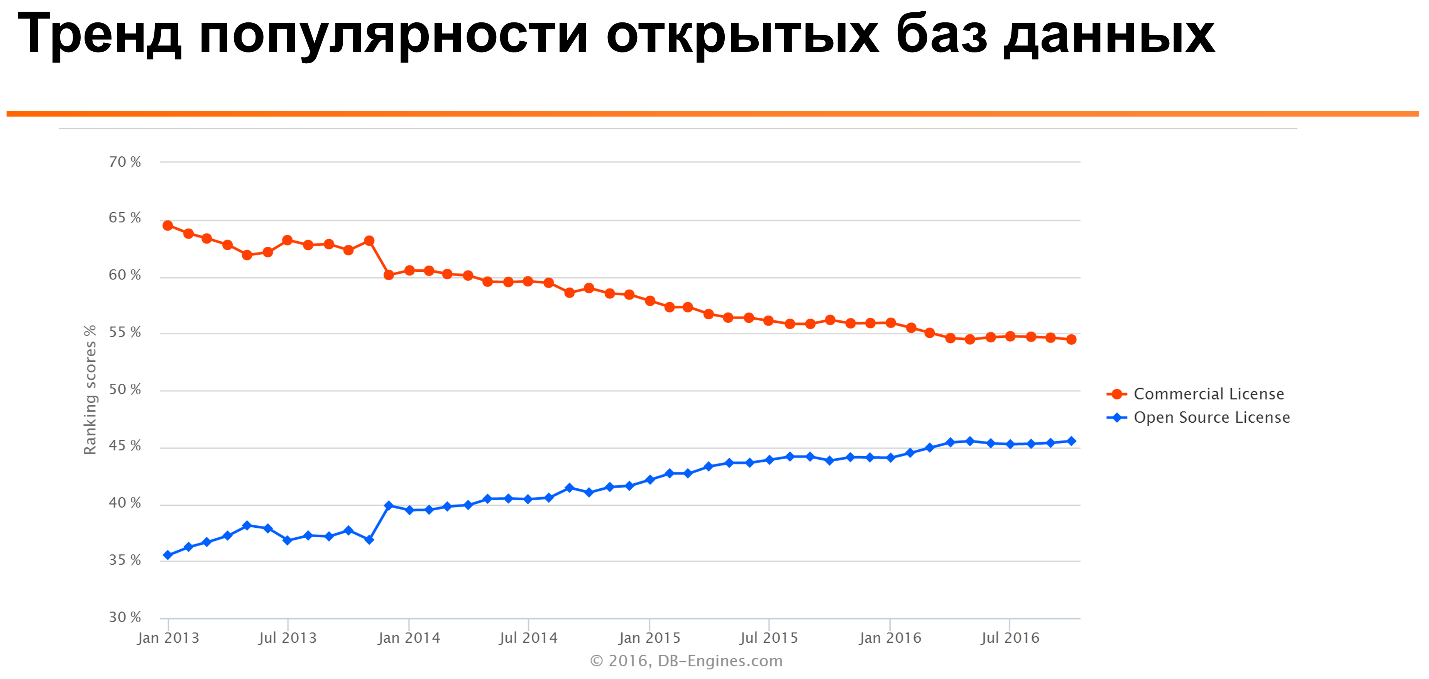
Если посмотреть такой известный
DB-Engines Ranking, то можно увидеть, что в течении многих лет популярность open source баз данных растет, а коммерческих — постепенно снижается.
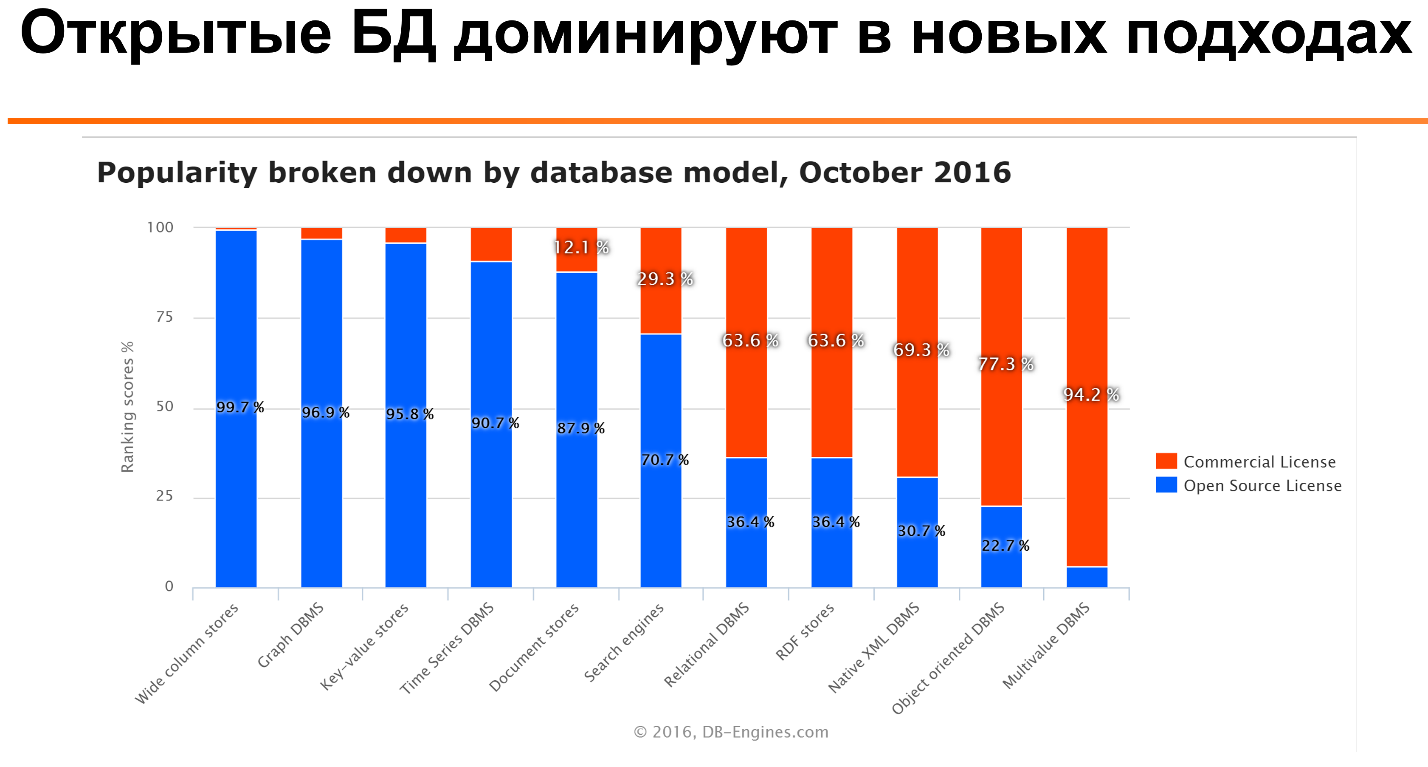
Что еще более интересно: если посмотреть на вот это отношение для разных типов баз данных, то видно, что для многих типов — таких, как колунарные базы данных, time series, document stories — open source базы данных наиболее популярны. Только для более старых технологий, таких как реляционные базы данных, или еще более древних, как multivalue база данных, коммерческие лицензии значительно популярнее.
Мы видим, что для многих приложений используют несколько баз данных для того, чтобы задействовать их сильные стороны. Ни одна база данных не оптимизирована для всех всевозможных юзкейсов. Даже если это PostgreSQL [смех на сцене и в зале].
С одной стороны, это хороший выбор, с другой — нужно пытаться найти баланс, так как чем у нас больше разных технологий, тем сложнее их поддерживать, особенно, если компания не очень большая.
Часто что видим, что люди приходят на такие конференции, слушают Facebook или «Яндекс» и говорят: «Ух ты! Сколько вот люди делают интересного. У них технологий разных используется штук 20, и еще штук 10 они написали сами». А потом они тот же самый подход пытаются использовать в своем стартапе из 10 человек, что работает, разумеется, не очень хорошо. Это как раз тот случай, где размер имеет значение.
Подходы к архитектуре
Очень часто мы видим, что используется основное операционное хранилище и какие-то дополнительные сервисы. Например, для кэширования или полнотекстового поиска.
Другой подход к архитектуре с использованием разных баз данных — это микросервисы, у каждого из которых может быть своя база данных, которая лучше оптимизирована для задач именно этого сервиса. Как пример: основное хранилище может быть на MySQL, Redis и Memcache — для кэширования, Elastic Search или родной Sphinx — для поиска. И что-то вроде Kafka — чтобы передавать данные в систему аналитики, которая часто делалась на чём-то вроде Hadoop.
Если мы говорим про основное операционное хранилище, наверное, у нас есть два выбора. С одной стороны, мы можем выбрать реляционные базы данных, с языком SQL. С другой стороны — что-то нереляционное, а дальше уже смотреть на подвиды, которые доступы в данном случае.
Если говорить про NoSQL-модели данных, то их тоже достаточно много. Наиболее типичные — это либо key value, либо document, либо wide column базы данных. Примеры: Memcache, MongoDB, Cassandra, соответственно.
Почему в данном случае мы сравниваем именно MySQL и MongoDB? На самом деле причин несколько. Если посмотреть на Ranking баз данных, то мы видим, что MySQL, согласно этому рейтингу, — наиболее популярная реляционная база данных, а MongoDB — наиболее популярная нереляционная база данных. Поэтому их разумно сравнивать.
А ещё у меня есть наибольший опыт в использовании этих двух баз данных. Мы в Percona занимаемся плотно именно с ними, работаем с многими клиентами, помогаем им сделать такой выбор. Еще одна причина: обе технологии изначально ориентированы на разработчиков простых приложений. Для тех людей, для которых PostgreSQL — это слишком сложно.
Компания MongoDB изначально очень активно фокусировалась на пользователях MySQL. Поэтому очень часто у людей есть опыт использования и выбор между этими двумя технологиями.
В Percona кроме того, что мы занимаемся поддержкой, консалтингом для этих технологий, у нас есть достаточно много написанного open source софта для обеих технологий. На слайде можно посмотреть. Подробно я рассказывать об этом не буду.

Что следует обо мне лично: я занимаюсь MySQL значительно больше, чем MongoDB. Несмотря на то, что я постараюсь предоставить сбалансированный обзор с моей стороны, у меня могут быть какие-то предрасположенности к MySQL, так как его тараканы я знаю лучше.
Выбор MySQL и MongoDB
Вот список разных вопросов, которые на мой взгляд имеет смысл рассматривать. Сейчас из них рассмотрим каждый более детально.
Что наиболее важно на мой взгляд — это учитывать, какие есть опыт и предпочтения команды. Для многих задач подходят оба решения. Их можно сделать и так, и так, может быть несколько сложнее, может быть несколько проще. Но если у вас команда, которая долго работала с SQL-базами данных и понимает реляционную алгебру и прочее, может быть сложно перетягивать и заставлять их использовать нереляционные базы данных, такие как MongoDB, где нет даже полноценной транзакции.
И наоборот: если есть какая-то команда, которая использует и хорошо знает MongoDB, SQL-язык может быть для неё сложен. Также имеет смысл рассматривать как оригинальную разработку, так и дальнейшее сопровождение и администрирование, поскольку всё это в итоге важно в цикле приложения.
Какие есть преимущества у данных систем?
Если говорить про MySQL — это проверенная технология. Понятно, что MySQL используется крупными компаниями более 15 лет. Так как он использует стандарт SQL, есть возможность достаточно простой миграции на другие SQL-базы данных, если захочется. Есть возможность транзакций. Поддерживаются сложные запросы, включая аналитику. И так далее.
С точки зрения MongoDB, здесь преимущество то, что у нас гибкий JSON-формат документов. Для некоторых задач и каким-то разработчикам это удобнее, чем мучиться с добавлением колонок в SQL-базах данных. Не нужно учить SQL — для некоторых это сложно. Простые запросы реже создают проблемы. Если посмотреть на проблемы производительности, в основном они возникают, когда люди пишут сложные запросы с
JOIN в кучу таблиц и
GROUP BY. Если такой функциональности в системе нет, то создать сложный запрос получается сложнее.
В MongoDB встроена достаточно простая масштабируемость с использованием технологии шардинга. Сложные запросы если возникают, мы их обычно решаем на стороне приложения. То есть, если нам нужно сделать что-то вроде
JOIN, мы можем сходить выбрать данные, потом сходить выбрать данные по ссылкам и затем их обработать на стороне приложения. Для людей, которые знают язык SQL, это выглядит как-то убого и ненатурально. Но на самом деле для многих разработчики application-серверов такое куда проще, чем разбираться с
JOIN.
Подход к разработке и жизненный цикл приложений
Если говорить про приложения, где используется MongoDB, и на чём они фокусируются — это очень быстрая разработка. Потому что всё можно постоянно менять, не нужно постоянно заботиться о строгом формате документа.
Второй момент — это схема данных. Здесь нужно понимать, что у данных всегда есть схема, вопрос лишь в том, где она реализуется. Вы можете реализовывать схему данных у себя в приложении, потому что каким-то же образом вы эти данные используете. Либо эта схема реализуется на уровне базы данных.
Очень часто если у вас есть какое-то приложение, с данными в базе данных работает только это приложение. Например, мы сохраняем данные из этого приложения в эту базу данных. Схема на уровне приложения работает хорошо. Если у нас одни и те же данные используются многими приложениями, то это очень неудобно, сложно контролировать.
Здесь возникает также вопрос времени жизни приложения. С MongoDB хорошо делать приложения, у которых очень ограниченный цикл жизни. То есть если мы делаем приложение, которое живёт недолго, например, сайт для запуска фильма или олимпиады. Мы пожили несколько месяцев после этого, и это приложение практически не используется. Если приложение живёт дольше, то тут уже другой вопрос.
Если говорить про распределение преимуществ и недостатков MySQL и MongoDB с точки зрения цикла разработки приложения, то их можно представить так:
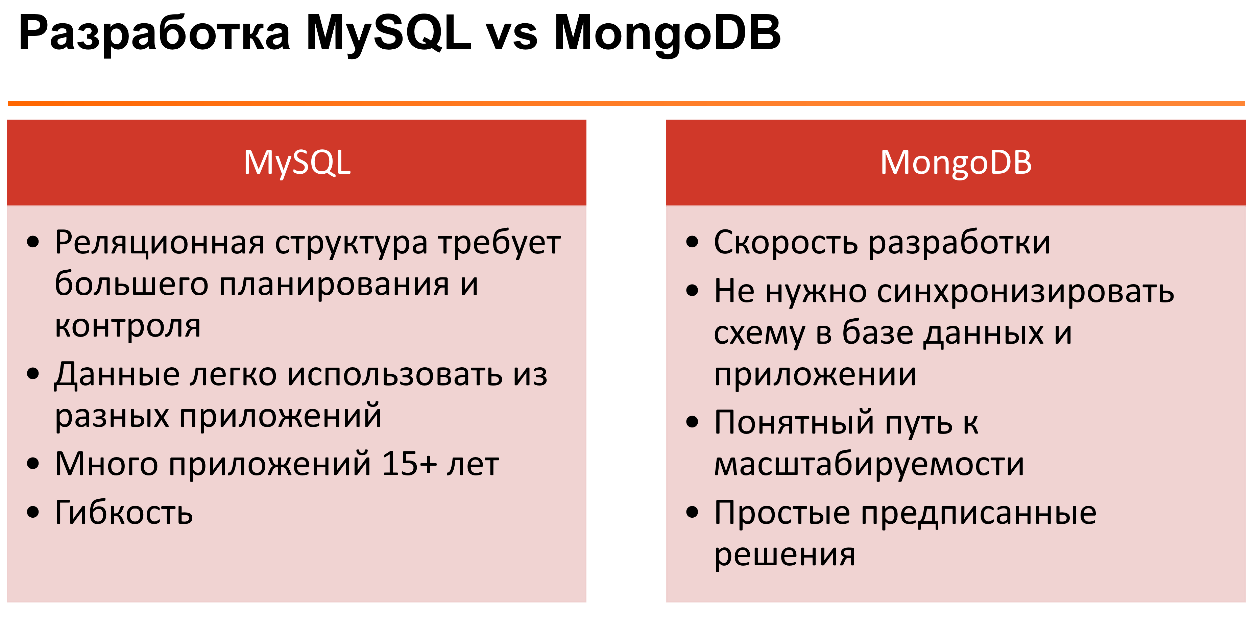
Модель данных очень сильно зависит от приложения и опыта команды. Было бы странным сказать, что у нас реляционный или нереляционный подход к базам данных лучше и лучше всегда.
Если сравнивать их между собой, то понятно, что у нас есть. В MySQL — реляционная база данных. Мы можем с помощью реляционной базы данных легко отображать связи между таблицами. Нормализуя данные, мы можем заставлять изменения данных происходить атомарно в одном месте. Когда данные у нас денормализованы, нам не нужно при каких-то изменениях бежать и модифицировать кучу документов.
Хорошо это или плохо? Результат — всегда таблица. С одной стороны, это просто, с другой — некоторые структуры данных не всегда хорошо ложатся на таблицу, нам может быть неудобно с этим работать.
Это всё в теории. Если говорить о практическом использовании MySQL, мы знаем, что часто денормализуем данные, иногда для некоторых приложений мы используем что-то подобное: храним JSON, XML или другую структуру в колонках приложения.
У MongoDB структура данных основана на документах. Данные многих веб-приложений отображать очень просто. Потому что если храним структуру — что-то вроде ассоциированного массива приложения, то это очень просто и понятно для разработчика сериализуется в JSON-документ. Раскладывать такое в реляционной базе данных по разным табличкам — задача более нетривиальная.
Результаты как список документов, у которых может быть совершенно разная структура — более гибкое решение.
Пример. Мы хотим сохранить контакт-лист с телефона. Понятно, что есть данные, которые хорошо кладутся в одну реляционную табличку: Фамилия, Имя и т.д. Но если посмотреть на телефоны или email-адреса, то у одного человека их может быть несколько. Если подобное хранить в хорошем реляционном виде, то нам неплохо бы это хранить в отдельных таблицах, потом это всё собирать
JOIN, что менее удобно, чем хранить это всё в одной коллекции, где находятся иерархические документы.

Следует сказать, что это всё в строго реляционной теории — некоторые базы данных поддерживают массивы. В MySQL поддерживается формат JSON, в который можно засунуть такие вещи, как несколько email-адресов. Или многие годы люди серилизовали это ручками: надо нам сохранить несколько email-адресов, то давайте запишем их через запятую, и дальше приложение разберётся. Но как-то это не очень кошерно.
Термины
Интересно, что между MySQL и MongoDB — вообще, между реляционными и нереляционными СУБД — что-то совпадает, что-то различается. Например, в обоих случаях мы говорим о базах данных, но то, что мы называем таблицей в реляционной базе данных, часто в нереляционной называется коллекцией. То, что в MySQL — колонка, в MongoDB — поле. И так далее.
С точки зрения использования
JOIN, в MongoDB нет такого понятия — это вообще понятие из реляционной структуры. Там мы либо делаем встроенный документ, что близко к концепту денормализации, либо мы просто сохраняем идентификатор документа в каком-то поле, называем это ссылкой и дальше ручками выбираем данные, которые нам нужны.
Что касается доступа: там, где мы к реляционным данным используем язык SQL, в MongoDB и многих других NoSQL-базах данных используется такой стандарт, как CRUD. Этот стандарт говорит, что есть операции для создания, чтения, удаления и обновления документов.
Несколько примеров.
Как у нас могут выглядеть наиболее типичные задачи по работе с документами в MySQL и MongoDB:
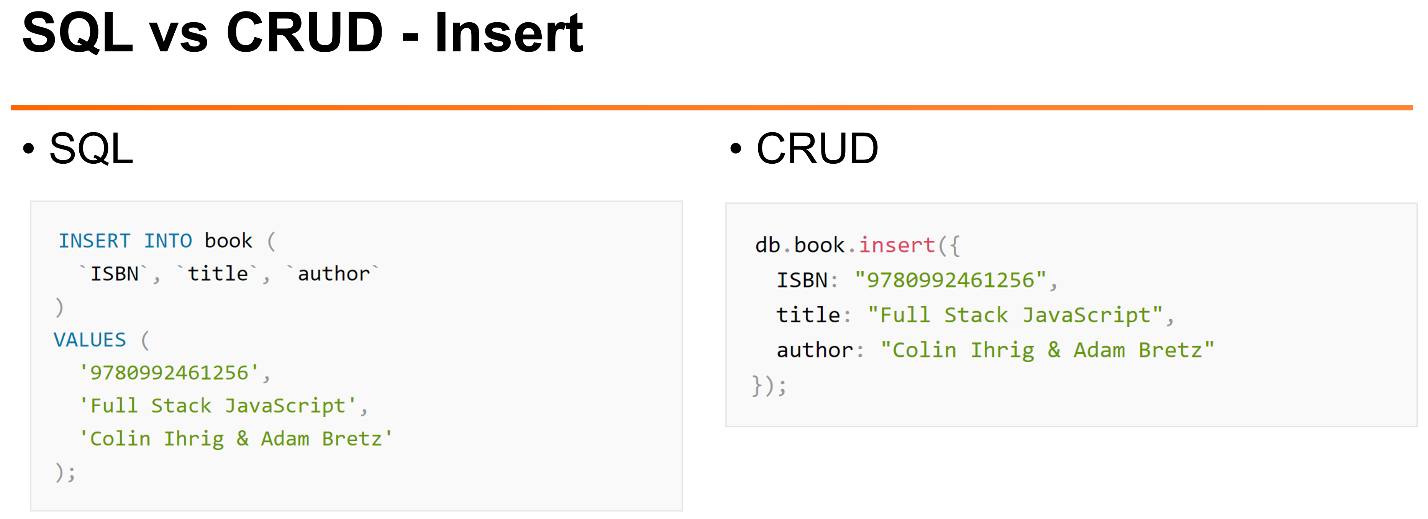
Вот пример вставки.
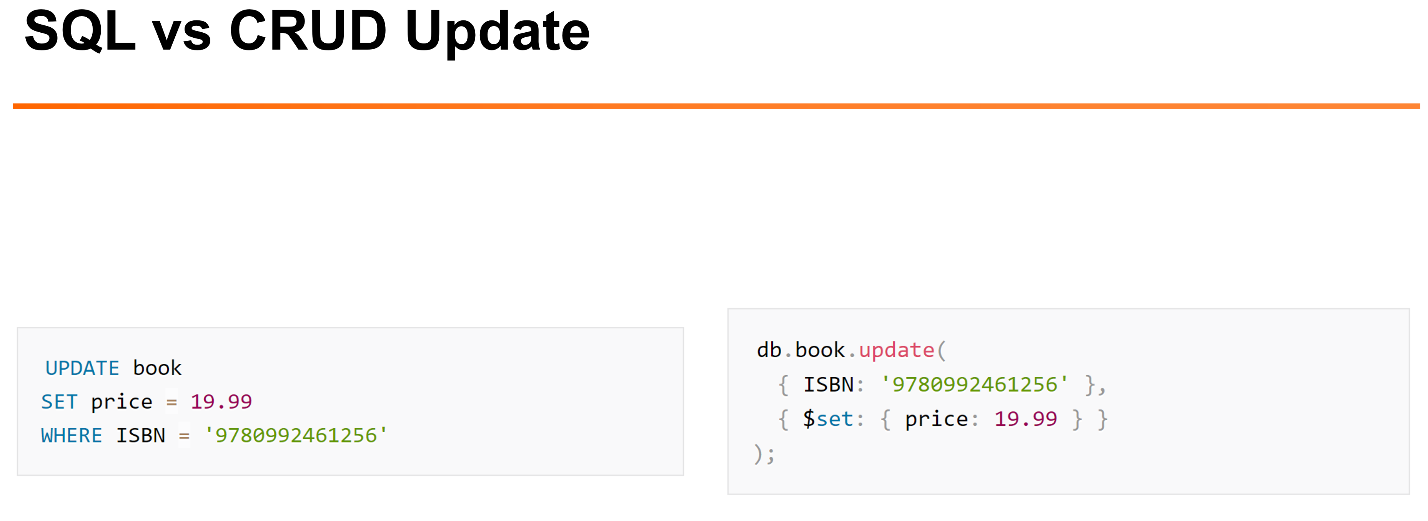
Пример обновления.
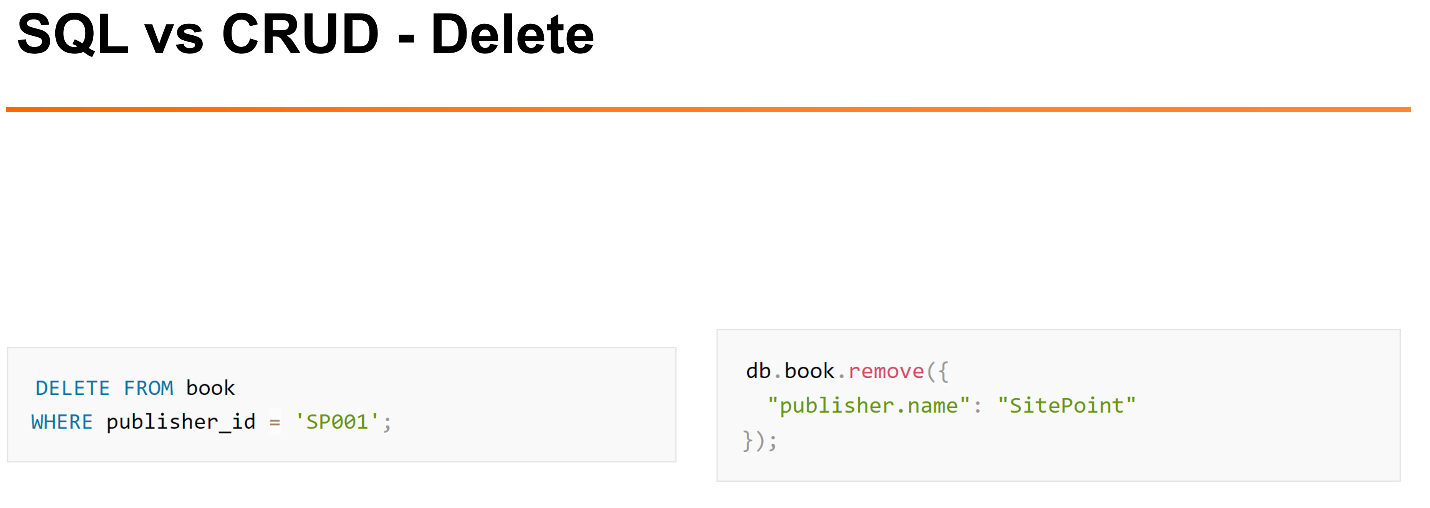
Пример удаления.
Если вы разработчик, который знаком с языком JavaScript, то такой синтаксис, который предоставляет CRUD (MongoDB), для вас будет более естественным, чем синтаксис SQL.
На мой взгляд, когда у нас есть простейшие операции: поиск, вставка, они все работают достаточно хорошо. Когда речь идёт о более интересных операциях выборки, на мой взгляд, язык SQL куда более читаемый.
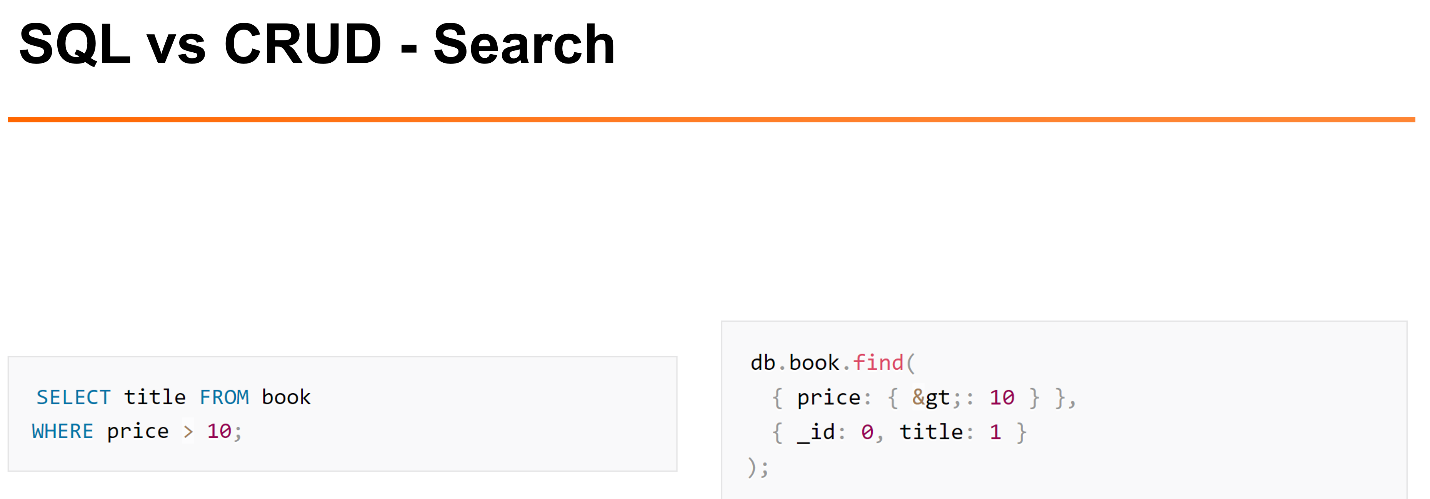
> вместо простого знака «>». Не очень читаемо, на мой взгляд.
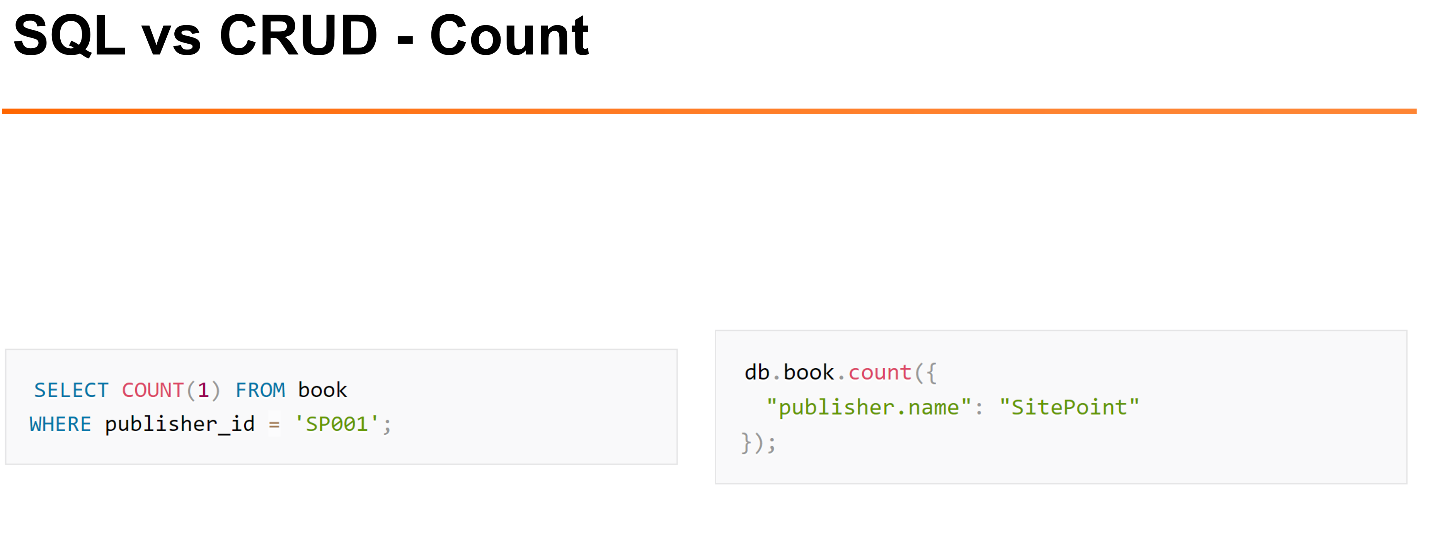
Достаточно легко с помощью интерфейса делать такие вещи, как подсчёт числа строк в таблице или коллекции.
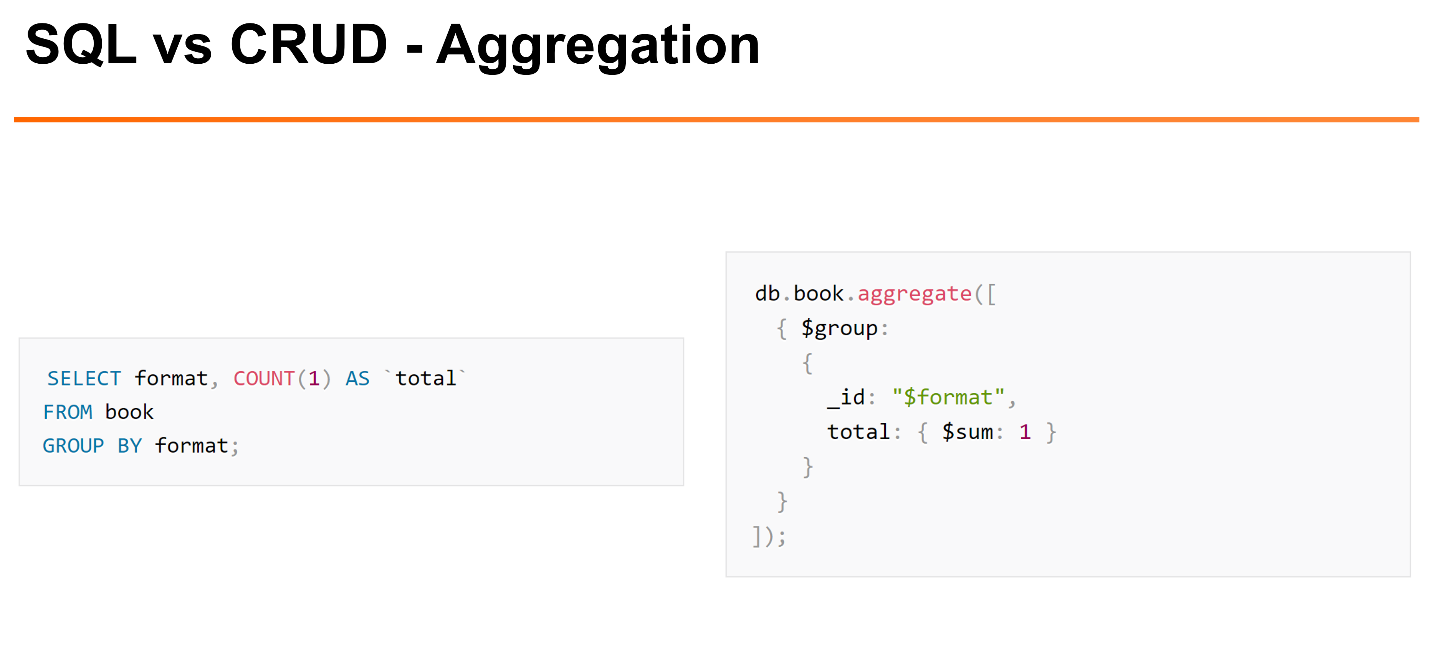
Но если мы делаем более сложные вещи, например,
GROUP BY, в MongoDB для этого требуется использовать Aggregation Framework. Это несколько более сложный интерфейс, который показывает, как мы хотим отфильтровать, как мы хотим группировать и т.д. Aggregation Framework уже поддерживает что-то вроде операций
JOIN.
Следующий момент — это транзакции и консистентность (ACID). Если пойти и почитать документацию MongoDB, там будет: «Мы поддерживаем ACID-транзакции, но с ограничением». На мой взгляд, стоит сказать: «ACID мы не поддерживаем, но поддерживаем другие минимальные нетранзакционные гарантии».
Какая у нас между ними разница?
Если говорить про MySQL, он поддерживает ACID-транзакции произвольного размера. У нас есть атомарность этих транзакций, у нас есть мультиверсионность, можно выбирать уровень изоляции транзакций, который может начинаться с
READ UNCOMMITED и заканчиваться
SERIALIZABLE. На уровне узла и репликаций мы можем конфигурировать, как данные хранятся.
Мы можем сконфигурировать у InnoDB, как работать с лог-файлом: сохранять его на диск при коммите транзакции или же делать это периодически. Мы можем сконфигурировать репликацию, включить, например, Semisynchronous Replication, когда у нас данные будут считаться сохранёнными только тогда, когда их копия будет принята на одном из slave’ов.
MongoDB не поддерживает транзакции, но он поддерживает атомарные операции над документом. Это значит, что с точки зрения одного документа операция у нас будет атомарна. Если у нас операция изменяет несколько документов, и во время этой операции произойдет какой-то сбой внутри, то какие-то из этих документов могут быть изменены, а какие-то — не изменены.
Консистентность тоже делается на уровне документов. В кластере мы можем выбирать гибкую консистентность. Мы можем указать, какие мы хотим гарантии — гарантии, что у нас данные были записаны только на один узел, или они были реплицированы на все узлы кластеров. Чтение консистентности тоже происходит на уровне документа.
Есть такой вариант обновления isolated, который позволяет выполнить обновление изолированно от других транзакций, но он очень неэффективен — он переключает базы данных в монопольный режим доступа, поэтому он используется достаточно редко. На мой взгляд, если говорить про транзакции и консистентность, то MongoDB достаточна убогая.
Производительность
Производительность очень сложно сравнивать напрямую, потому что мы часто делаем разные схемы баз данных, дизайн приложения. Но если говорить в целом, MongoDB изначально была сделана, чтобы хорошо масштабироваться на много узлов через шардинг, поэтому эффективности было уделено меньше внимания.
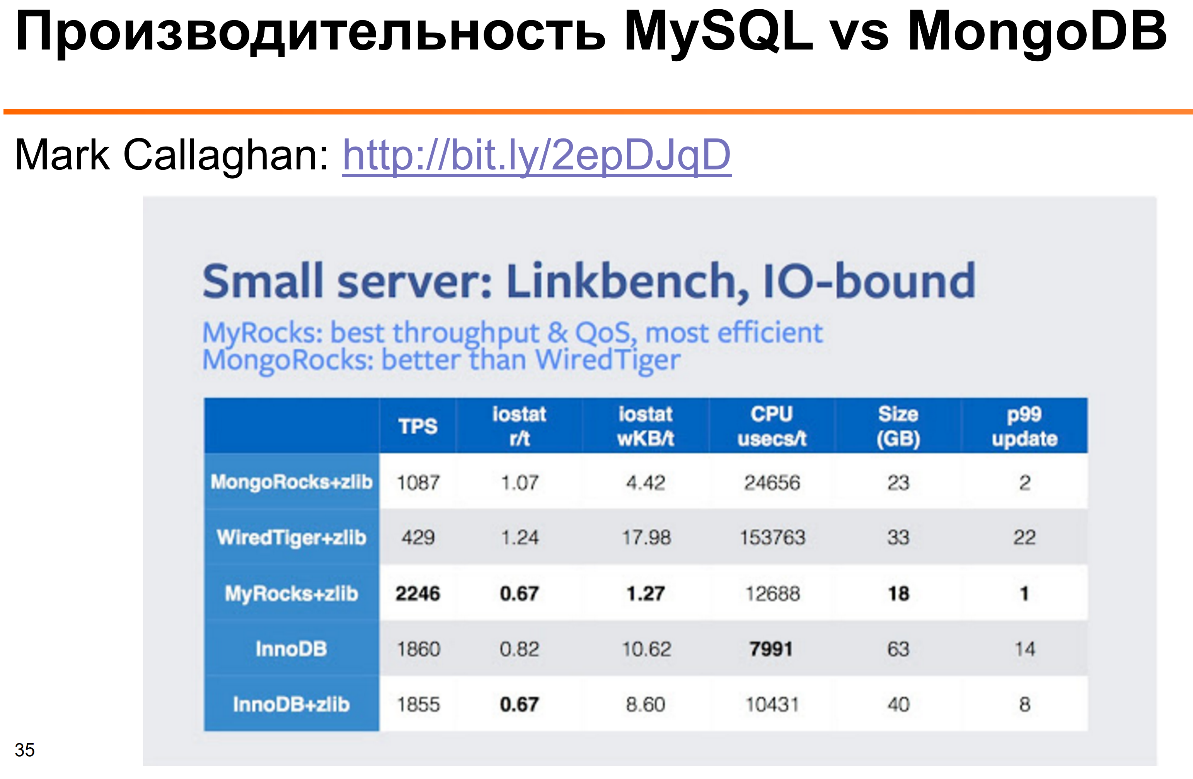
Это результаты бенчмарка, который делал Марк Каллаган. Здесь видно, что с точки зрения использования процессора, ввода/вывода MySQL — как InnoDB, так и MyRocks — использует значительно меньше процессора и дискового ввода/вывода на операции бенчмарка Linkbench от Facebook.
Масштабируемость.
Что такое масштабируемость в данном контексте? То, насколько легко нам взять наше маленькое приложение и масштабировать его на многие миллионы, может быть, даже на миллиарды пользователей.
Масштабируемость бывает разная. Она бывает средняя, в рамках одной машины, когда мы хотим поддерживать приложения среднего размера, либо масштабируемость на кластере, когда у нас приложения уже очень большие, когда понятно, что даже одна самая мощная машина не справится.
Также имеет смысл говорить о том, масштабируем ли мы чтение, запись или объем данных. В разных приложениях их приоритеты могут различаться, но в целом, если приложение очень большое, обычно им приходится работать со всеми из этих вещей.
В MySQL в новых версиях весьма хорошая масштабируемость в рамках одного узла для LTP-нагрузок. Если у нас маленькие транзакции, есть какое-нибудь железо, в котором 64 процессора, то масштабируется достаточно хорошо. Аналитика или сложные запросы масштабируются плохо, потому что MySQL может использовать для одного запроса только один поток, что плохо.
Традиционно чтение в MySQL масштабируется с репликацией, запись и размер данных — через шардинг. Если смотреть на все большие компании — Facebook, Twitter — они все используют шардинг. Традиционно шардинг в MySQL используется вручную. Есть некоторые фреймворки для этого. Например, Vitess — это фреймворк, который Google использует для scaling сервиса YouTube, они его выпустили в open source. До этого был framework Jetpants. Стандартного решения для шардинга MySQL не предлагает, часто переход на шардинг требует внимания от разработчиков.
В MongoDB фокус изначально был в масштабируемости на многих узлах. Даже в случаях с маленьким приложением многим рекомендуется использовать шардинг с самого начала. Может, всего пару replica set, потом вы будете расти вместе со своим приложением.
В шардинге MongoDB есть некоторые ограничения: не все операторы с ним работают, например, есть isolated-вариант для обеспечения консистентности. Она не работает если использовать шардинг. Но при этом многие основные операции хорошо работают в шардингом, поэтому людям позволяется scale’ить приложения значительно лучше. На мой взгляд, шардинг и вообще репликация в MongoDB сделаны куда лучше, чем MySQL, значительно проще в использовании для пользователя.
Администрирование
Администрирование – это все те вещи, о которых не думают разработчики. По крайней мере в первую очередь. Администрирование — это то, что нам приложение придётся бэкапить, обновлять версии, мониторить, восстановливать при сбоях и так далее.
MySQL достаточно гибок, у него есть много разных подходов. Есть хорошие open source реализации всего, но это множество вариантов порождает сложность. Я часто общаюсь с пользователями, которые только начинают изучать MySQL. Они говорят: «Ёлки-палки, сколько же у вас всего вариантов. Вот только репликация — какую мне использовать: statement-репликацию, raw-репликацию, или mix? А еще есть gtid и стандартная репликация. Почему нельзя сказать „просто работай“?»
В MongoDB всё больше ориентированно на то, что оно работает каким-то одним стандартным образом — есть минимизация администрирования. Но понятно, что это происходит при потере гибкости. Коммьюнити open source решений для MongoDB значительно меньше. Многие вещи в MongoDB с точки зрения рекомендаций достаточно жестко привязаны к Ops Manager — коммерческой разработке MongoDB.
Мифы
Как в MongoDB, так и в MySQL есть мифы, которые были в прошлом, которые были исправлены, но у людей хорошая память, особенно если что-то не работает. Помню, в MySQL после того как появились транзакции с InnoDB, люди мне лет десять говорили: «А в MySQL нет же транзакций?»
В MongoDB было много разных проблем с производительностью MMAP storage engine: гигантские блокировки, неэффективное использование дискового пространства. Сейчас в стандартном движке WiredTiger уже нет многих из этих проблем. Есть другие проблемы, но не эти.
«Нет контроля схемы» — ещё такой миф. В новых версиях MongoDB можно для каждой коллекции определить на JSON структуру, где данные будут валидироваться. Данные, которые мы пытаемся вставить, и они не соответствуют какому-то формату, можно выкидывать.
«Нет аналога
JOIN» — то же самое. В MongoDB это появилось, но нескольких ограниченных вещах. Только на уровне одного шарда и только если мы используем Aggregation Framework, а не в стандартных запросах.
Какие у нас есть мифы в MySQL? Здесь я буду говорить больше о поддержке NoMySQL решений в MySQL, об этом я буду говорить завтра. Следует сказать, что MySQL сейчас тоже можно использовать через интерфейс CRUD’a, использовать в NoSQL режиме примерно как MongoDB.
Типичный пример, где используется MySQL-решение — это сайт электронной коммерции. Когда у нас идёт вопрос о деньгах, часто мы хотим полноценные транзакции и консистентность. Для таких вещей хорошо подходит реляционная структура, которая была проработана, и commerce на реляционных базах данных уже делается многие десятилетия. Так что можно взять один из готовых подходов к структуре данных и использовать его.
Обычно с точки зрения e-commerce объем данных у нас не такой большой, так что даже достаточно большие магазины могут долго работать без шардинга. Приложения у нас постоянно разрабатываются и усовершенствуется на протяжении многих лет. И у этого приложения много компонент, которые работают с одними и теми же данными: кто-то рассчитывает, где цены поменять, кто-то ещё что-то делает.
MongoDB часто задействуется как бэкенд больших онлайн-игр. Electronic Arts для очень многих игр использует MongoDB. Почему? Потому что масштабируемость важна. Если какая-то игра хорошо выстрелит, её приходится масштабировать значительно больше, чем предполагалось.
С другой стороны, если не выстрелит, нам хотелось бы, чтобы инфраструктуру можно было бы уменьшить. Во многих играх это идет так: мы запустили игру, у нее есть какой-то пик, приходится делать большой кластер. Потом игра уже выходит из популярности, для неё бэкенд нужно сжимать, сохранять и использовать. В данном случае есть одно приложение (игра), база данных, с одной стороны, несложная, с другой — сильно привязанная к приложению, в котором хранятся все важные для игры параметры.
Часто консистентность базы данных на уровне объектов здесь достаточна, потому что многие вопросы консистентости решаются на уровне приложения. Например, данные одного игрока сохраняет только один application service.
Петр Зайцев показывает разницу между MySQL и MongoDB.
Дополнительная информация
Всем рекомендую это старое, древнее, но очень смешное видео
http://www.mongodb-is-web-scale.com/ [
YouTube]. На этом мы закончим.
MySQL и MongoDB — когда что лучше использовать?