
В нашем блоге на Хабре мы не только рассказываем о развитии своего продукта —биллинга для операторов связи «Гидра», но и публикуем материалы о работе с инфраструктурой и использовании технологий.
Недавно мы писали об использовании Clojure и MongoDB, а сегодня речь пойдет о плюсах и минусах денормализации баз данных. Разработчик баз данных и финансовый аналитик Эмил Дркушич (Emil Drkušić) написал в блоге компании Vertabelo материал о том, зачем, как и когда использовать этот подход. Мы представляем вашему вниманию главные тезисы этой заметки.
Непременное условие процесса денормализации — наличие нормализованной базы. Важно понимать различие между ситуацией, когда база данных вообще не была нормализована, и нормализованной базой, прошедшей затем денормализацию. Во втором случае — все хорошо, а вот первый говорит об ошибках в проектировании или недостатке знаний у специалистов, которые этим занимались.
Рассмотрим нормализованную модель для простейшей CRM-системы:
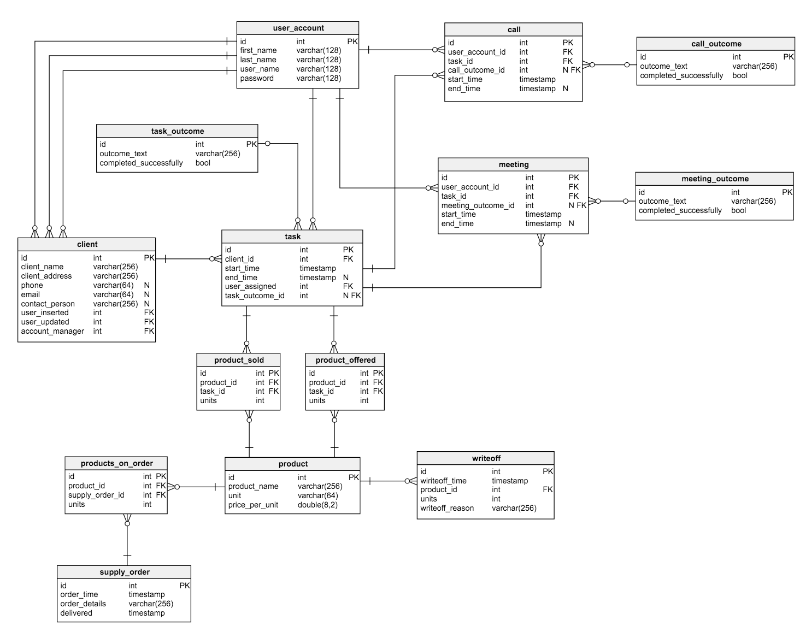
Пробежимся по имеющимся здесь таблицам:
В этом примере база данных сильно упрощена для наглядности. Но нетрудно увидеть, что она отлично нормализована — в ней нет никакой избыточности, и все должно работать, как часы. Никаких проблем с производительностью не возникает до того момента, пока база не столкнется с большим объёмом данных.
Прежде чем браться разнормализовывать то, что уже однажды было нормализовано, естественно, нужно четко понимать, зачем это нужно? Следует убедиться, что выгода от применения метода перевешивает возможные негативные последствия. Вот несколько ситуаций, в которых определенно стоит задуматься о денормализации.
Вывод напрашивается сам собой: не следует обращаться к денормализации, если не стоит задач, связанных с производительностью приложения. Но если чувствуется, что система замедлилась или скоро замедлится, впору задуматься о применении данной техники. Однако, прежде чем обращаться к ней, стоит применить и другие возможности улучшения производительности: оптимизацию запросов и правильную индексацию.
Очевидная цель денормализации — повышение производительности. Но всему есть своя цена. В данном случае она складывается из следующих пунктов:
В представленной модели были применены некоторые из вышеупомянутых правил денормализации. Синим отмечены новые блоки, розовым — те, что были изменены.
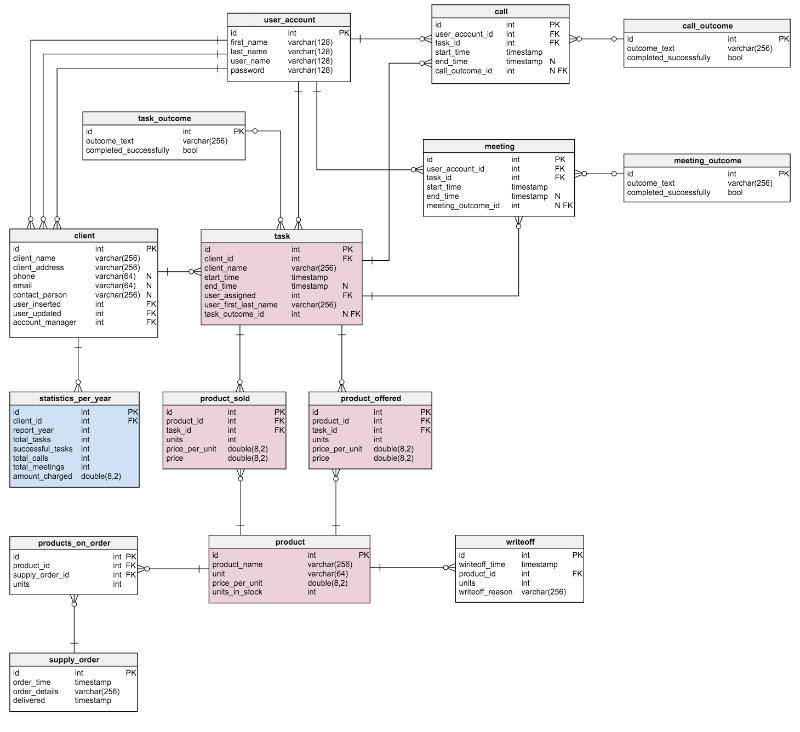
Что изменилось и почему?
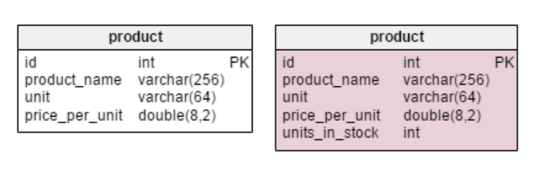
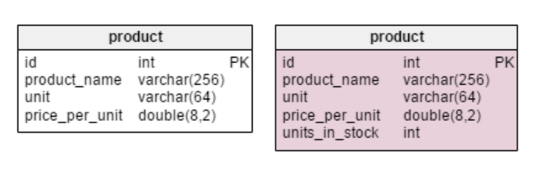
Единственное нововведение в таблице
В таблицу
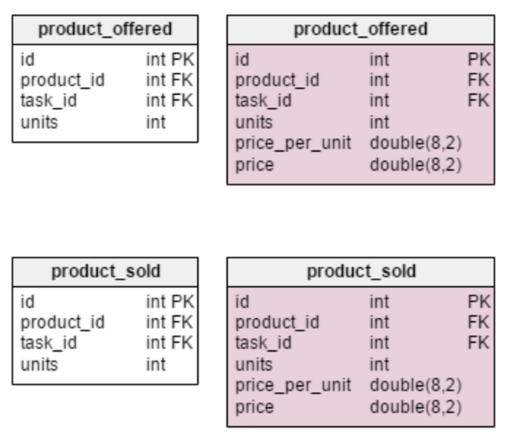
Денормализованная таблица
Изменения в таблице
Таблица
Денормализация — мощный подход. Не то чтобы к ней следует прибегать каждый раз, когда стоит задача увеличения производительности. Но в отдельных случаях это может быть лучшим или даже единственным решением.
Однако, прежде, чем принять окончательное решение об использовании денормализации, следует убедиться в том, что это действительно необходимо. Нужно провести анализ текущей производительности системы — часто денормализацию применяют уже после запуска системы в работу. Не стоит этого бояться, однако следует внимательно отслеживать и документировать все вносимые изменения, тогда проблем и аномалий данных не должно возникнуть.
Мы в Латере много занимаемся оптимизацией производительности нашей биллинговой системы «Гидра», что неудивительно, учитывая объемы наших клиентов и специфику телеком-отрасли.
Один из примеров в статье предполагает создание таблицы с промежуточными итогами для ускорения отчетов. Конечно, самое сложное в этом подходе — поддерживать актуальное состояние такой таблицы. Иногда можно переложить эту задачу на СУБД — например, использовать материализованные представления. Но, когда бизнес-логика для получения промежуточных результатов оказывается чуть более сложной, актуальность денормализованных данных приходится обеспечивать вручную.
«Гидра» имеет глубоко проработанную систему привилегий для пользователей, операторов биллинга. Права выдаются несколькими способами — можно разрешить определенные действия конкретному пользователю, можно заранее подготовить роли и выдать им разные наборы прав, можно наделить определенный отдел специальными привилегиями. Только представьте, насколько медленными стали бы обращения к любым сущностям системы, если бы каждый раз нужно было пройти всю эту цепочку, чтобы убедиться: «да, этому сотруднику разрешено заключать договоры с юридическими лицами» или «нет, у этого оператора недостаточно привилегий для работы с абонентами соседнего филиала». Вместо этого мы отдельно храним готовый агрегированный список действующих прав для пользователей и обновляем его, когда в систему вносятся изменения, способные на этот список повлиять. Сотрудники переходят из одного отдела в другой намного реже, чем открывают очередного абонента в интерфейсе биллинга, а значит вычислять полный набор их прав нам приходится настолько же реже.
Конечно, денормализация хранилища — это только одна из принимаемых мер. Часть данных стоит кэшировать и непосредственно в приложении, но если промежуточные результаты в среднем живут намного дольше, чем пользовательские сессии, есть смысл всерьез задуматься о денормализации для ускорения чтения.
Недавно мы писали об использовании Clojure и MongoDB, а сегодня речь пойдет о плюсах и минусах денормализации баз данных. Разработчик баз данных и финансовый аналитик Эмил Дркушич (Emil Drkušić) написал в блоге компании Vertabelo материал о том, зачем, как и когда использовать этот подход. Мы представляем вашему вниманию главные тезисы этой заметки.
Что такое денормализация?
Обычно под этим термином понимают стратегию, применимую к уже нормализованной базе данных с целью повышения ее производительности. Смысл этого действия — поместить избыточные данные туда, где они смогут принести максимальную пользу. Для этого можно использовать дополнительные поля в уже существующих таблицах, добавлять новые таблицы или даже создавать новые экземпляры существующих таблиц. Логика в том, чтобы снизить время исполнения определенных запросов через упрощение доступа к данным или через создание таблиц с результатами отчетов, построенных на основании исходных данных.Непременное условие процесса денормализации — наличие нормализованной базы. Важно понимать различие между ситуацией, когда база данных вообще не была нормализована, и нормализованной базой, прошедшей затем денормализацию. Во втором случае — все хорошо, а вот первый говорит об ошибках в проектировании или недостатке знаний у специалистов, которые этим занимались.
Рассмотрим нормализованную модель для простейшей CRM-системы:
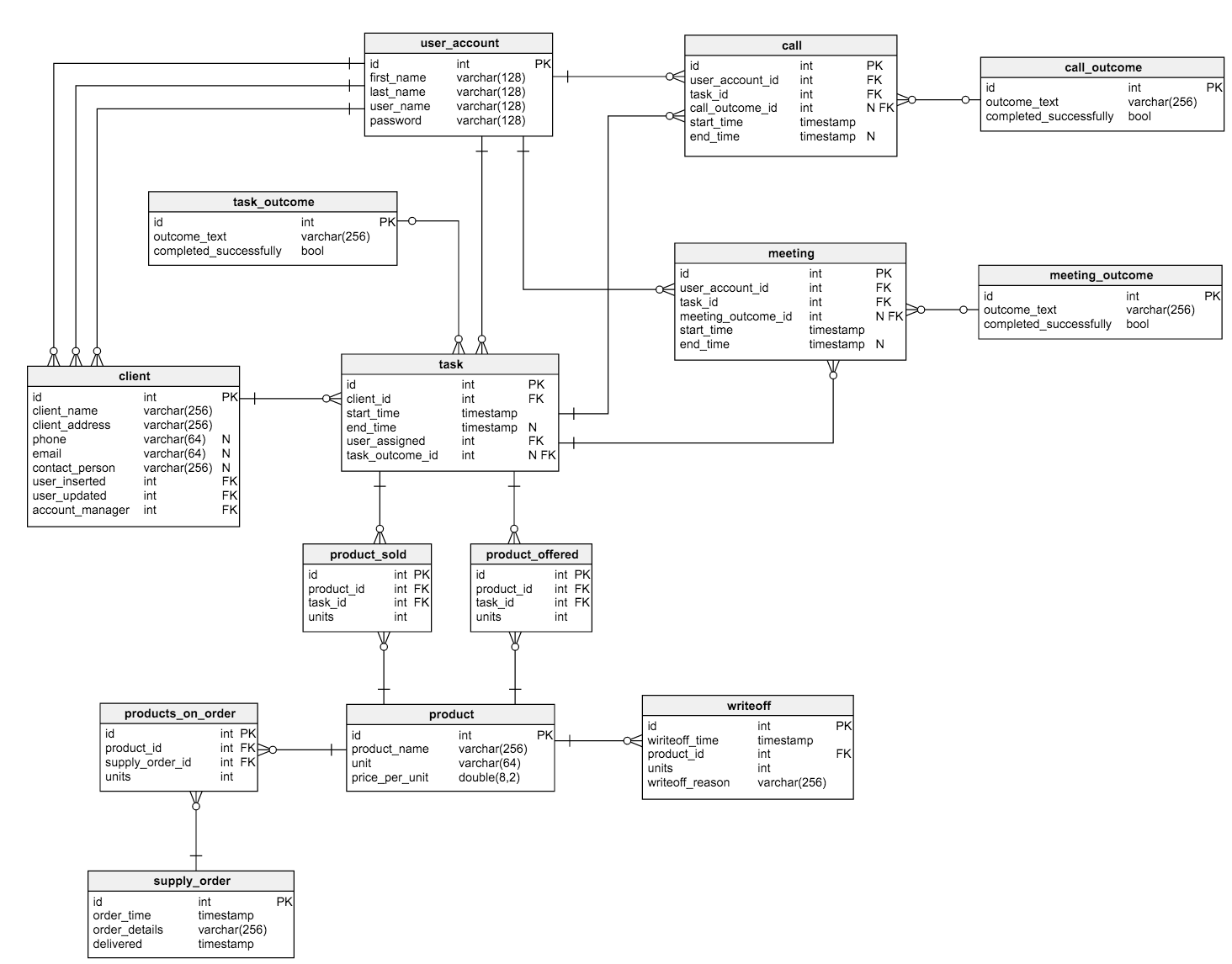
Пробежимся по имеющимся здесь таблицам:
- Таблица
user_accountхранит данные о пользователях, зарегистрированных в приложении (для упрощения модели роли и права пользователей из нее исключены). - Таблица
clientсодержит некие базовые сведения о клиентах. - Таблица
product— это список предлагаемых товаров. - Таблица
taskсодержит все созданные задачи. Каждую из них можно представить в виде набора согласованных действий по отношению к клиенту. Для каждой есть список звонков, встреч, предложенных и проданных товаров. - Таблицы
callиmeetingхранят данные о заказах и встречах с клиентами и связывают их с текущими задачами. - Словари
task_outcome,meeting_outcomeиcall_outcomeсодержат все возможные варианты результата звонков, встреч и задания. product_offeredхранит список продуктов, которые были предложены клиентам;product_sold— продукты, которые удалось продать.- Таблица
supply_orderхранит информацию обо всех размещенных заказах. - Таблица
writeoffсодержит перечень списанных по каким-либо причинам товаров.
В этом примере база данных сильно упрощена для наглядности. Но нетрудно увидеть, что она отлично нормализована — в ней нет никакой избыточности, и все должно работать, как часы. Никаких проблем с производительностью не возникает до того момента, пока база не столкнется с большим объёмом данных.
Когда полезно использовать денормализацию
Прежде чем браться разнормализовывать то, что уже однажды было нормализовано, естественно, нужно четко понимать, зачем это нужно? Следует убедиться, что выгода от применения метода перевешивает возможные негативные последствия. Вот несколько ситуаций, в которых определенно стоит задуматься о денормализации.
- Сохранение исторических данных. Данные меняются с течением времени, но может быть нужно сохранять значения, которые были введены в момент создания записи. Например, могут измениться имя и фамилия клиента или другие данные о его месте жительства и роде занятий. Задача должна содержать значения полей, которые были актуальны на момент создания задачи. Если этого не обеспечить, то восстановить прошлые данные корректно не удастся. Решить проблему можно, добавив таблицу с историей изменений. В таком случае SELECT-запрос, который будет возвращать задачу и актуальное имя клиента будет более сложным. Возможно, дополнительная таблица — не лучший выход из положения.
- Повышение производительности запросов. Некоторые запросы могут использовать множество таблиц для доступа к часто запрашиваемым данным. Пример — ситуация, когда необходимо объединить до 10 таблиц для получения имени клиента и наименования товаров, которые были ему проданы. Некоторые из них, в свою очередь, могут содержать большие объемы данных. При таком раскладе разумным будет добавить напрямую поле
client_idв таблицуproducts_sold. - Ускорение создания отчетов. Бизнесу часто требуется выгружать определенную статистику. Создание отчетов по «живым» данным может требовать большого количества времени, да и производительность всей системы может в таком случае упасть. Например, требуется отслеживать клиентские продажи за определенный промежуток по заданной группе или по всем пользователям разом. Решающий эту задачу запрос в «боевой» базе перелопатит ее полностью, прежде чем подобный отчет будет сформирован. Нетрудно представить, насколько медленнее все будет работать, если такие отчеты будут нужны ежедневно.
- Предварительные вычисления часто запрашиваемых значений. Всегда есть потребность держать наиболее часто запрашиваемые значения наготове для регулярных расчетов, а не создавать их заново, генерируя их каждый раз в реальном времени.
Вывод напрашивается сам собой: не следует обращаться к денормализации, если не стоит задач, связанных с производительностью приложения. Но если чувствуется, что система замедлилась или скоро замедлится, впору задуматься о применении данной техники. Однако, прежде чем обращаться к ней, стоит применить и другие возможности улучшения производительности: оптимизацию запросов и правильную индексацию.
Не все так гладко
Очевидная цель денормализации — повышение производительности. Но всему есть своя цена. В данном случае она складывается из следующих пунктов:
- Место на диске. Ожидаемо, поскольку данные дублируются.
- Аномалии данных. Необходимо понимать, что с определенного момента данные могут быть изменены в нескольких местах одновременно. Соответственно, нужно корректно менять и их копии. Это же относится к отчетам и предварительно вычисляемым значениям. Решить проблему можно с помощью триггеров, транзакций и хранимых процедур для совмещения операций.
- Документация. Каждое применение денормализации следует подробно документировать. Если в будущем структура базы поменяется, то в ходе этого процесса нужно будет учесть все прошлые изменения — возможно, от них вообще можно будет к тому моменту отказаться за ненадобностью. (Пример: в клиентскую таблицу добавлен новый атрибут, что приводит к необходимости сохранения прошлых значений. Чтобы решить эту задачу, придется поменять настройки денормализации).
- Замедление других операций. Вполне возможно, что применение денормализации замедлит процессы вставки, модификации и удаления данных. Если подобные действия проводятся относительно редко, то это может быть оправдано. В этом случае мы разбиваем один медленный SELECT-запрос на серию более мелких запросов по вводу, обновлению и удалению данных. Если сложный запрос может серьезно замедлить всю систему, то замедление множества небольших операций не отразится на качестве работы приложения столь драматических образом.
- Больше кода. Пункты 2 и 3 потребуют добавления кода. В то же время они могут существенно упростить некоторые запросы. Если денормализации подвергается существующая база данных, то потребуется модифицировать эти запросы, чтобы оптимизировать работу всей системы. Также понадобится обновить существующие записи, заполнив значения добавленных атрибутов — это тоже потребует написания некоторого количества кода.
В представленной модели были применены некоторые из вышеупомянутых правил денормализации. Синим отмечены новые блоки, розовым — те, что были изменены.

Что изменилось и почему?
Единственное нововведение в таблице
product — строка units_in_stock. В нормализованной модели мы можем вычислить это значение следующим образом: заказанное наименование — проданное — (предложенное) — списанное (units ordered — units sold — (units offered) — units written off). Вычисление повторяется каждый раз, когда клиент запрашивает товар. Это довольно затратный по времени процесс. Вместо этого можно вычислять значение заранее так, чтобы к моменту поступления запроса от покупателя, все уже было наготове. С другой стороны, атрибут units_in_stock должен оновляться после каждой операции ввода, обновления или удаления в таблицахproducts_on_order, writeoff, product_offered и product_sold.В таблицу
task добавлено два новых атрибута: client_name иuser_first_last_name. Оба они хранят значения на момент создания задачи — это нужно, потому что каждое из них может поменяться с течением времени. Также нужно сохранить внешний ключ, который связывает их с исходным пользовательским и клиентским ID. Есть и другие значения, которые нужно хранить — например, адрес клиента или информация о включенных в стоимость налогах вроде НДС.Денормализованная таблица
product_offered получила два новых атрибута:price_per_unit и price. Первый из них необходим для хранения актуальной цены на момент предложения товара. Нормализованная модель будет показывать лишь ее текущее состояние. Поэтому, как только цена изменится, изменится и «ценовая история». Нововведение не просто ускорит работу базы, оно улучшает функциональность. Строка price вычисляет значение units_sold * price_per_unit. Таким образом, не нужно делать расчет каждый раз, как понадобится взглянуть на список предложенных товаров. Это небольшая цена за увеличение производительности.Изменения в таблице
product_sold сделаны по тем же соображениям. С той лишь разницей, что в данном случае речь идет о проданных наименованиях товара.Таблица
statistics_per_year (статистика за год) в тестовой модели — абсолютно новый элемент. По сути, это денормализованная таблица, поскольку все ее данные могут быть рассчитаны из других таблиц. Здесь хранится информация о текущих задачах, успешно выполненных задачах, встречах, звонках по каждому заданному клиенту. В данном месте также хранится общая сумма проведенных начислений за каждый год. После ввода, обновления или удаления любых данных в таблицах task,meeting, call и product_sold приходится пересчитывать эти данные для каждого клиента и соответствующего года. Так как изменения, скорее всего, касаются лишь текущего года, отчеты за предыдущие годы теперь могут оставаться без изменений. Значения в этой таблице вычисляются заранее, поэтому мы сэкономим время и ресурсы, когда нам понадобятся результаты расчетов.Денормализация — мощный подход. Не то чтобы к ней следует прибегать каждый раз, когда стоит задача увеличения производительности. Но в отдельных случаях это может быть лучшим или даже единственным решением.
Однако, прежде, чем принять окончательное решение об использовании денормализации, следует убедиться в том, что это действительно необходимо. Нужно провести анализ текущей производительности системы — часто денормализацию применяют уже после запуска системы в работу. Не стоит этого бояться, однако следует внимательно отслеживать и документировать все вносимые изменения, тогда проблем и аномалий данных не должно возникнуть.
Наш опыт
Мы в Латере много занимаемся оптимизацией производительности нашей биллинговой системы «Гидра», что неудивительно, учитывая объемы наших клиентов и специфику телеком-отрасли.
Один из примеров в статье предполагает создание таблицы с промежуточными итогами для ускорения отчетов. Конечно, самое сложное в этом подходе — поддерживать актуальное состояние такой таблицы. Иногда можно переложить эту задачу на СУБД — например, использовать материализованные представления. Но, когда бизнес-логика для получения промежуточных результатов оказывается чуть более сложной, актуальность денормализованных данных приходится обеспечивать вручную.
«Гидра» имеет глубоко проработанную систему привилегий для пользователей, операторов биллинга. Права выдаются несколькими способами — можно разрешить определенные действия конкретному пользователю, можно заранее подготовить роли и выдать им разные наборы прав, можно наделить определенный отдел специальными привилегиями. Только представьте, насколько медленными стали бы обращения к любым сущностям системы, если бы каждый раз нужно было пройти всю эту цепочку, чтобы убедиться: «да, этому сотруднику разрешено заключать договоры с юридическими лицами» или «нет, у этого оператора недостаточно привилегий для работы с абонентами соседнего филиала». Вместо этого мы отдельно храним готовый агрегированный список действующих прав для пользователей и обновляем его, когда в систему вносятся изменения, способные на этот список повлиять. Сотрудники переходят из одного отдела в другой намного реже, чем открывают очередного абонента в интерфейсе биллинга, а значит вычислять полный набор их прав нам приходится настолько же реже.
Конечно, денормализация хранилища — это только одна из принимаемых мер. Часть данных стоит кэшировать и непосредственно в приложении, но если промежуточные результаты в среднем живут намного дольше, чем пользовательские сессии, есть смысл всерьез задуматься о денормализации для ускорения чтения.
Источник: https://habrahabr.ru/company/latera/blog/281262/
Смотри также:
- Sublime Text: Подсветка синтаксиса и объектов БД. http://fetisovvs.blogspot.com/2015/12/sublime-text.html
- Сравнение производительности MariaDB 10.1 и MySQL 5.7. http://fetisovvs.blogspot.com/2015/10/mariadb-101-mysql-57.html
- Балансировка MySQL. http://fetisovvs.blogspot.com/2015/08/mysql.html
- Лицензирование баз данных. Часть 1. http://fetisovvs.blogspot.com/2015/02/blog-post_11.html
- DbForge Studio for MySQL - удобный набор инструментов для профессиональной разработки и управления MySQL базы данных. http://fetisovvs.blogspot.com/2014/10/dbforge-studio-for-mysql-mysql.html
- Основы работы с DbForge Studio - инструментом для работы с MySQL. http://fetisovvs.blogspot.com/2014/11/dbforge-studio-mysql.html
- В SQL будут добавлены средства для работы с многомерными массивами данных. http://fetisovvs.blogspot.com/2014/07/sql.html
- Немного об оптимизации запросов. http://fetisovvs.blogspot.com/2015/10/blog-post_42.html
- На пути к правильным SQL транзакциям. http://fetisovvs.blogspot.com/2015/06/sql.html
- Компания SkySQL переименована в MariaDB Corporation http://fetisovvs.blogspot.ru/2014/10/skysql-mariadb-corporation.html
- Работа с PostgreSQL настройка и масштабирование (справочное пособие). http://fetisovvs.blogspot.com/2014/08/postgresql.html
- Электронная книга Инсталляция MySQL 5.5.24 http://fetisovvs.blogspot.com/2014/09/mysql-5524.html
Комментариев нет:
Отправить комментарий