
Петр Зайцев (Percona)
Сегодня мы поговорим о производительности.Мы посмотрим на то, как подойти правильно к оптимизации MySQL, а также посмотрим на некоторые практические подходы к этому делу. Почему я считаю, что это важно? Дело в том, что когда у вас есть специфическая проблема, вы хотите, например, спросить: «А какой же мне установить размер кэша в MySQL?». Такой вопрос всегда можно ввести в Google или Yandex, и получить на него разумный ответ. Но как получить ответ об общем, о схеме анализа и оптимизации MySQL? Это куда более сложно.

Первая вещь, о которой нужно знать, что производительность MySQL сама по себе на самом деле не важна. И вот я смотрю, молодой человек сзади улыбается: «Как же так? Важна, вроде. О чем же мы говорим, если она не важна?».

На самом деле вашим пользователям, вашему боссу важна, прежде всего, производительность вашего приложения, которое использует MySQL, а может использовать какие-то другие системы. И это то, на чем имеет смысл фокусироваться, потому что если вы смотрите на проблему с точки зрения приложения, то вам открываются некоторые другие, более широкие подходы. Может, MySQL не использовать в некоторых случаях, или использовать его не так.

Также важно, что производительность приложений важна всегда. В каких-то случаях я говорю с людьми, и они мне говорят: «Вот, вы знаете, это у нас отчет. Нам его производительность не важна, занимает он у нас минуту, две или три – нас все устроит». Но если их спросить: «Ребята, а если этот отчет у вас займет месяц, устроит вас это?». Они говорят: «Нет, конечно, не устроит». Значит, производительность важна, просто в головах некоторых людей важная производительность – это значит, что мы можем выполнить какой-нибудь запрос за миллисекунды или за секунды. Люди часто не думают, что даже те процессы, которые занимают минуты и часы, тоже могут быть критичны по производительности. А почему это важно? Потому что часто, когда мы делаем какие-то алгоритмы баз данных, пишем какие-нибудь запросы, их сложность может возвращать нелинейно относительно объема данных. Т.е. может быть, что у нас объем данных вырос всего лишь в 10 раз, а скорость выполнения запроса увеличилась в 100 раз. Создавая сюрприз и неожиданность, что такие тормоза мы совершенно не ожидали.

Что еще важно? То, что производительность и приложения могут быть не обязательно связаны с MySQL. С этим у меня тоже есть интересный случай. Я помню, прихожу к клиенту, смотрю на их MySQL-сервер. И, вроде бы, у них как бы все нормально, длинных запросов нет, загрузка сервера меньше чем 10%, и я их спрашиваю: «Ребята, а почему вы думаете, что это вообще MySQL?» – «Ну, вот сколько мы лет занимаемся, всегда все проблемы производительности – это всегда с MySQL, поэтому мы туда и копаем». Иногда да, но в каких-то случаях и нет.
Еще важно, что даже если проблемы с MySQL, часто решения могут быть не связаны с MySQL. Например, многие из вас знают Андрея Аксенова из Sphinx. Большая часть его бизнеса, особенно в первые годы – это спасать MySQL-пользователей, которые пытались долго и упорно использовать MySQL full text search. Но этот слоник не летает, как с ним не стараться, не пытаться его заставить работать, не скейлится он. В этом случае для таких задач как полнотекстовый поиск использовать Sphinx – это более разумное решение.

И таких инструментов на самом деле много сейчас, которые позволяют решать разные задачи, которые MySQL решает не очень хорошо. Т.е. full text search, есть Sphinx elastic Search – другой вариант. Для каких-то задач Redis или Tarantool подходит куда лучше. Если мы говорим об аналитике данных, то здесь часто подходит решение Hadoop или же Vertica, или каких-то систем, которые нормально обрабатывают данные параллельно. Потому что MySQL любой запрос выполняет только в один поток на одном сервере, что, понятно, на большие объемы совсем не скейлится.

Когда мы говорим о производительности, о чем мы думаем? Прежде всего мы думаем о времени отклика. Почему? Потому что если вы посмотрите на вашего эгоистичного пользователя, то это то, о чем он думает прежде всего. Т.е. если я захожу на веб-сайт или работаю с приложением, и это приложение мне отвечает быстро, то это все, что меня волнует. Ваши всякие queries per second, число запросов в секунду и прочая фигня пользователя интересует мало.

Т.е. прежде всего мы смотрим на приложение и хотим, чтобы оно пользователю отвечало со временем отклика, которое может быть разным для разных приложений, для разных задач. Нет какой-то определенной цифры, что время отклика за полсекунды – это хорошо, а все, что больше – плохо.
Но если мы говорим о реальных приложениях, то часто мы рассматриваем не только время отклика, но и другие вещи. Первый вопрос, что мы хотим, чтобы это время отклика было стабильное. Т.е. с очень многими случаями я сталкиваюсь, что проблема не в том, что время отклика плохое всегда, а в том, что у нас иногда что-то происходит с системой или внешне, которое его ухудшает. Например, часто люди жалуются, что у меня все хорошо работает, но когда я запустил backup, у меня все начинает быть плохо. Надо за такими вещами следить. Или же бывает часто связано с какими-то вещами вроде всплеска загрузки, т.е., может, веб-сайт показали в какой-нибудь известной телевизионной передаче или кто-нибудь еще его упомянул, трафик хлынул, система не справляется.
Следующий вопрос, который мы часто задаем по производительности – это масштабируемость. Многие-многие приложения начинают с достаточно маленьких систем. Маленький объем данных, маленький объем пользователей, у них в планах расти. Нам важно, чтобы те алгоритмы, те запросы, те дизайны, схемы, которые мы используем, не только работали сейчас, но и работали на приложение будущего. И некоторые подходы, которые наиболее оптимальны сегодня, на текущем объеме данных, могут быть хороши, но не скейлятся.
И третий момент – это эффективность, которая тоже важна. Эффективность как с точки зрения использования ресурсов, так и с точки зрения людей, которые требуются для создания этой архитектуры. Например, интересный вариант с Hadoop. Сейчас Hadoop уже лучше, но традиционно, когда Hadoop только начинался, он скейлился на тысячи и тысячи узлов. Но если сравнить эффективность, например, MySQL с Hadoop, то MySQL на одном узле мог сделать то же самое, что Hadoop на десяти. И понятно, что если объем данных достаточно маленький, то использовать MySQL было бы куда более эффективно. Но если нам нужно то, что на один сервер не влазит, то с точки зрения Hadoop, мы можем запустить 1000 или 10 000 узлов. С MySQL мы так поступить не сможем.
С точки зрения нашей масштабируемости мы уже поговорили про нагрузку, про размер данных, и еще важна масштабируемость с точки зрения инфраструктуры. О чем здесь стоит сказать? Что в зависимости от того, в каком вы работаете режиме, вам может быть доступна та или иная инфраструктура. Например, во многих облачных сетях мы не можем так легко масштабироваться вверх. Там сложно сказать: «Я хочу поставить сервер, в котором у нас будет 64 ядра, 1 Тб памяти, 4 очень-очень быстрые флэш-карточки, чтобы я мог 10 Тб локального быстрого флэша получить». Если вы работаете в своем дата-центре, и у вас есть выбор инфраструктуры, вы можете получить это, вы можете подключить такой сервер с 40 Гб Ethernet, или даже не один. Если вы работаете в cloud, то у вас могут быть совершенно другие ограничения, с которыми приходится работать.

Следующий момент, с которым мы часто сталкиваемся. Когда мы разрабатываем реальные приложения, часто у нас производительность – это важная вещь, но это не единственная вещь, о которой приходится заботиться. Например, безопасность. Безопасность, криптование трафика обычно производительность не улучшает, но, наоборот, это те вещи, которые могут снижать производительность, с которыми придется мириться.
Управляемость – другой момент. Т.е. часто наиболее оптимизированный код и структуры – его фиг поймешь потом. Во многих случаях мы сталкиваемся, что люди не хотят супер оптимизировать производительность, если это делает код слишком сложным. И есть другие разные вещи, с которыми приходится считаться. Например, часто могут быть какие-нибудь потребности аудита, в связи с которыми любые изменения данных должны протоколироваться, что добавляет еще дополнительных функций, которые стоят нам чего-то с точки зрения производительности.

Следующий момент, который стоит упомянуть. Это то, что производительность – это та вещь, которую можно улучшать бесконечно. Нет такой системы, которая максимально оптимизирована, и в которой, затратив много денег и времени, нельзя еще улучшить производительность хотя бы на несколько процентов. Это означает, что нам нужно всегда знать, когда остановится, иначе мы просто будем тратить ресурсы совершенно бесполезно. Это значит, что нужно каким-то образом нам определить, какая нам требуется эффективность, производительность системы и т.д. И когда она достигнута, мы можем остановиться.
Следующий момент. Переходя уже к MySQL. Мы говорили, что важно время отклика системы. Теперь давайте посмотрим, что же MySQL, вообще, делает для своих пользователей. А делает он очень простое – мы выполняем запросы на MySQL, селекты, апдейты, инсерты, и он нам через какое-то время откликается. И все, что связано с производительностью MySQL, может быть характеризовано этим откликом на запросы.
Понятно, при разных нагрузках, при разных объемах данных и т.д. Но если мы смотрим на эти запросы и смотрим на их время отклика и фокусируемся на этом в плане оптимизации, мы получим те результаты, которые возможно получить.
Когда мы говорим об оптимизации MySQL? Наверное, стоит сказать одну вещь, которой нет на этом слайде. Это о том, что лучший вопрос что-то оптимизировать – это этого не делать. Очевидно, вы это много от кого слышали, но, что интересно с точки зрения MySQL, что если я приду к большинству людей, мы возьмем приложение включим MySQL-лог и загрузим страничку. В большинстве случаев я найду несколько запросов, которые будут повторяться. Вы знаете, что их можно легко удалить, потому что второй запрос делать бесполезно. Часто я увижу, что данные запрашиваются из базы данных и приложением не используются. Но почему? – «Ну, вот, у меня там этот класс инициализируется, он все поднимает из базы данных, на всякий случай, а на самом деле это мы не используем». Очень часто в приложениях делается куча-куча мусора, которая никому не нужна. Но что, когда мы фокусируемся на оптимизации, над чем мы часто работаем? Первый, очень простой момент, что мы хотим, чтобы наши вопросы выполнялись быстрее, другой момент – мы хотим, чтобы они использовали меньше ресурсов, например, меньше памяти, или с помощью компрессии мы можем оптимизировать систему, чтобы она использовала меньше места на диске. Или же лучше масштабируемость с точки зрения железа, с точки зрения размера данных и т.д.

Если мы говорим об оптимизации и общем подходе, часто мы смотрим на две вещи. Первое – это оптимизация-транзакция. Например, у вас есть приложение, и кто-то говорит: «Вы знаете, у нас есть такая функция поиска или архив, которая тормозит, работает медленнее, чем нам хотелось». Мы можем посмотреть конкретно эту функцию, какие она запросы делает на MySQL, и их оптимизировать. Другой вариант – сказать, а давайте, мы приложение соптимизируем в общем. Тогда мы можем взять посмотреть на все запросы, которые приходят на MySQL, посмотреть, какие из них наиболее медленные, которые используют больше всего ресурсов, и когда мы их оптимизируем, то очевидно, что у нас система будет работать быстрее в общем. Но при этом, если мы используем второй подход, у нас нет гарантий, насколько наш этот тормозной процесс будет оптимизирован, потому что, может быть, что именно он и не создает много нагрузки, может, это какая-то аналитика, которую большой босс смотрит раз в день, и она составляет 0,01% нагрузки, но, тем не менее, она весьма важна.

И понятно, что с точки зрения общей оптимизации мы смотрим на запросы, мы их приоритезируем и дальше их оптимизируем.

С точки зрения запросов. Как я уже говорил, первый вопрос с точки зрения запросов: можем ли мы этих запросов избежать? Потому что часто какие-то запросы бесполезны. Второй вопрос: можем ли мы эти запросы изменить, чтобы они делали меньше работы? Что значит меньше работы? Это значит, чтобы они сканировали меньше строчек, читали меньше данных с диска и т.д. – все это мы называем простым словом «работа».
Какой у нас может быть пример? У нас есть запрос, который выполняется без индекса, он делает очень много работы. Индекс мы добавили – запрос делает меньше работы. Когда это действительно настолько просто, что добавить индекс или изменить настройки MySQL. В других случаях это может быть что-то более сложное, например, у нас может быть плохая схема данных, которая не позволяет нам добавить индекс, чтобы запрос выполнялся быстро. Тогда нам приходится изменять схему данных, а не только индексы запросов. Иногда нам придется применить какие-то другие подходы, например, кэширование. Мы можем кэшировать данные, мы можем сделать какую-то summary table, таблицу, в которую мы прогенерировали все наши результаты, вместо того, чтобы лопатить данные много-много раз каждую секунду.

Следующий вопрос по оптимизации: что важно? Первое – не стоит смотреть только на среднее время выполнения запросов. Потому что среднее время выполнения любого запроса редко проблема, прежде всего, проблема начинается с какими-то, не хочу сказать с экстремальными, но близкими к тому условиями. Например, я помню ребята из Flickr (относительно старый, но крупный хостинг для картинок) рассказывали, что у них проблемы возникли, когда какой-то товарищ залил им 1 млн. картинок через API. Понятно, то, что работало для нормальных пользователей – нормально, в категории 1 тыс., 100 картинок, с 1 млн. картинок уже не работает. С точки зрения среднего запроса, среднего пользователя, это бы не показалось.
Следующий момент – то, что мы хотим тоже смотреть на тренды со временем, потому что некоторые проблемы возникают циклично, может, это связано с месячным биллингом, может, это связанно с тем, что вы раз в неделю удаляете старые данные, и это может показывать проблемы.
Опять-таки, когда мы смотрим запросы, следует думать о будущем. Особенно в development-системах. Я очень часто сталкиваюсь с тем, что разработчики тестируют запросы на каких-то маленьких базах данных в своей конфигурации для тестов и не очень хорошо читают explain в MySQL. В этом случае, когда их запросы выкладываются на продакшн или чуть позже, когда данные начинают резко расти, все это ломается. Нужно учиться читать explain и думать, а как же эти запросы будут работать в будущем.
Следующий момент. Понятно, что мы хотим использовать меньше запросов. Даже если мы анализируем то же самое число строк, то чем меньше запросов мы можем использовать, тем лучше. Потому что с каждым запросом у нас добавляется время отклика сети, у нас добавляется дополнительный оверхед на парсинг запросов, на проверку привилегий и прочее. Мы тоже хотим читать и модифицировать как можно меньше данных. Т.е. если мы можем выполнить запрос лимит 10, например, то это куда лучше, чем считать все данные, просто прочитать несколько первых строчек в приложении, а все остальное выкинуть.
То же самое касается, что лучше считывать только те столбцы в базе данных, те колонки, которые приложение реально использует. Потому что MySQL в этих случаях может использовать другие дополнительные оптимизации и выполнять запросы более эффективно.
Дальше. Чем меньше можем обрабатывать данных во время выполнения запросов, тем лучше. Опять-таки, тяжелые запросы, которые делают какие-то сложные агрегации каждый раз для каждого пользователя – это не очень хорошо для большой агрегации, лучше посмотреть, как мы можем это создать как таблицы с кэшем и т.д.
На что можно смотреть? Какие у нас есть интересные метрики? Первая – это мы можем посмотреть, сколько данных MySQL проанализировал относительно того, сколько он их послал клиенту. Эту метрику легко получить из MySQL. Есть для каждого запроса, например, в slow query log данные Rows_sent и Rows_examined. Отношение между ними – это то, на что мы хотим смотреть. Если у нас отношение где-нибудь там от 1 до 10, приложение в целом обычно оптимизировано хорошо. Если мы на каждую строчку, которую мы посылаем из MySQL, обрабатываем 100, а то и 1 тыс., то, скорее всего, у нас есть много возможностей для оптимизации.
Следующий момент – это посмотреть, сколько у нас данных реально было послано с MySQL относительно того, сколько было использовано приложением. Здесь, к сожалению, метрики, которые дает MySQL нет, потому что MySQL данные отдал, и он уже не знает, как вы их используете. Но часто на это вы можете посмотреть сами, по крайней мере, для наиболее тяжелых запросов, которые возвращают очень много данных. Т.е. если вы считали 1 млн. строк на приложение, следует хорошо подумать, а все ли вы их там используете? Вряд ли на одной странице показывается 1 млн. элементов. Может, они как-то агрегируются и в этом случае часто эту работу лучше делать на базе данных.

Следующий момент. Как мы уже говорили, не всегда удается запросы оптимизировать, просто добавив индекс, часто нам приходится менять схему более кардинально, поэтому часто имеет смысл смотреть на оптимизацию схемы и оптимизацию запросов вместе. И здесь есть две вещи:
- это небольшие оптимизации схемы – добавить индекс, может, изменить тип колонки или еще что-нибудь, изменить storage enigne в MySQL;
- сильное изменение схемы и всей архитектуры, которое тоже иногда бывает нужно, но оно обычно требует значительно более серьезного планирования. Т.е. если вы делаете полный реинжиниринг вашей схемы, то это занимает существенное время.
С точки зрения схемы баз данных. Нужно знать, как работают индексы. Я даю ссылку на мою презентацию по этому поводу.
Следующий момент. Когда вы разрабатываете схему, думайте о том, какие запросы у вас будут выполняться. Очень часто я смотрю, что люди делают, в коде используют IR тулзу, которая им делает совершенно абстрактную и «академически» правильную структуру базы данных, которая, к сожалению, не работает. С этого можно начинать, но этим редко удается закончить. Надо смотреть, как на этом работают ваши запросы, и уже дальше думать. И разные техники можете посмотреть, Partitioning & Sharding, нормализация, денормализация данных и т.д. Эти вещи нужно ввести в Google и про них прочитать.

Другие вещи, которые у нас тоже имеют важное значение – конечно, инфраструктура, ОС, MySQL-версия, MySQL-конфигурация. И мы поговорим об этом чуть более подробно.
Если у нас есть система, которую нужно оптимизировать, как к этому подходим мы, когда нас часто зовут с точки зрения консалтинга? Во-первых, есть вещи простые, которые можно изменить очень быстро, и этого часто достаточно. Изменить настройки MySQL, может, ОС, добавить какие-то индексы, может быть, включить какое-нибудь кэширование – и это те вещи, которые часто можно сделать буквально за часы.
Следующий вопрос, который более сложный, если нам нужно купить новое железо или сделать какие-нибудь переконфигурации сети, изменить ОС на более новую или проапгрейдить MySQL. Это более сложные вещи, которые занимают дни.
И, наконец, бывают случаи, когда так все плохо, когда даже этого не хватает. Тогда нам нужно перейти уже к тяжелой артиллерии, нам, может, приходится совершенно переделывать схемы базы данных, или же нам приходится изменить архитектуру приложения, сказать, что «знаете, мы теперь делаем шардинг, для этого мы вообще решаем MySQL не использовать» и т.д.
Если вы посмотрите на многие приложения, которые росли, они часто проходят через такие шаги.
Про инфраструктуру. Здесь нужно понимать, какие у вас опции, можете ли вы скейлится с одним узлом какое-то время, или же вам нужно переходить на архитектуру, которая может работать на многих маленьких машинах, как, например, часто в облачных структурах.
Что у нас важно с точки зрения железа? Нам важны вот эти компоненты:

С точки зрения процессора. Понятно, что сейчас серверные процессоры – это Intel. C MySQL мы видим, что чаще всего используется система с двумя сокетами для процессоров. Что еще важно? Поскольку MySQL может использовать для одного запроса только одно ядро процессора, то часто для нас быстрые процессоры более важны, чем процессоры, в которых много, но медленных кор. Часто это забывается. И также смотрите на такую штуку как turboboost, потому что современные процессоры, если из них используются не все коры, а только одна-две, то они часто могут работать на значительно более высокой тактовой частоте. И часто для нас важна не номинальная частота процессора, а до скольки они будут делать turboboost, потому что если мы будем выполнять тяжелые запросы, но которые использую только одну кору – это то, что будет ограничивать производительность.
Память. Когда мы используем память базы данных, мы ее используем для кэша. Поэтому если данных у вас много, то нам хочется, чтобы памяти тоже было много. Здесь о чем имеет смысл думать – о том, какое соотношение между размером базы данных и памяти. Вся ли она у нас влазит или же какая-то ее часть. Имеет смысл также смотреть на то, какая часть активно используемых данных у вас влазит в память. Понятно, что часто у нас есть большая база данных, но ее серьезная часть используется очень редко, ее держать в памяти дорого, поэтому когда я смотрю на то, насколько хорошо база данных влазит в память, я не смотрю реально на отношение размера базы данных в памяти, но, скорее, на то, сколько у нас операций ввода-вывода происходит. Особенно на чтение, потому что если у нас вся активно используемая база данных в памяти, то операций чтения, которые в дисковой подсистеме, у нас практически не будет.
Следующий для вас интересный достаточно график:
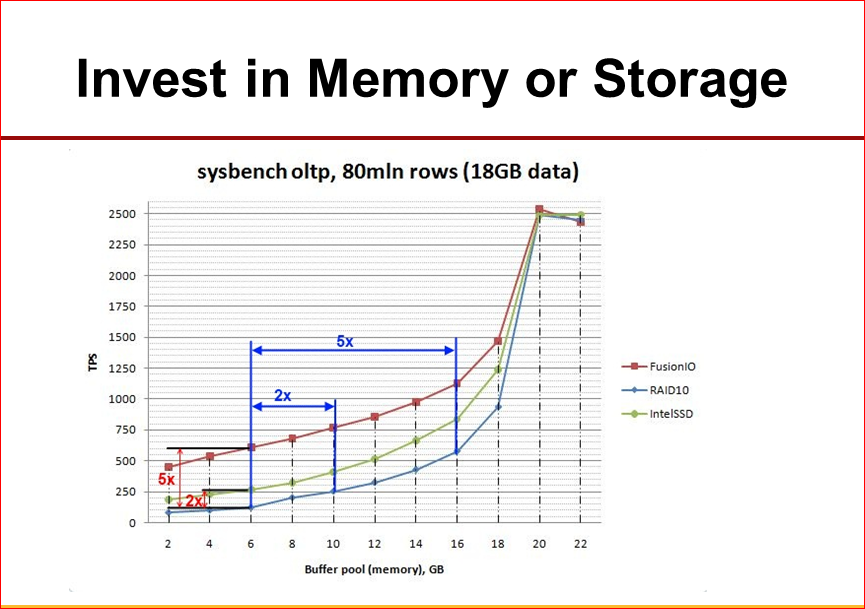
Здесь мы смотрели поведение определенного синтетического бенчмарка с разными объемами памяти и разной конфигурацией системы накопителей. Т.е. у нас синяя – это RAID, самый медленный, красная – это самый быстрый FusionIO. Что мы видим интересного? Если база данных плохо влазит в память, то быстрый сторадж у нас дает очень большое преимущество, т.е. мы видим, что разница в 5 раз внизу. Но когда у нас данные влазят в память все лучше и лучше, то у нас разница между быстрым и медленным стораджами сокращается. Из этого вывод: если у нас есть шанс загнать наш working set в память, то лучше инвестировать в память. Иметь какой-нибудь флаш, но, может быть, не самый быстрый. Но если у вас объем данных уже такой, что в память загонять все равно не удается, то в этом случае часто имеет смысл иметь несколько меньше памяти, но иметь более быстрый сторадж.
Что стоит сказать про сторадж? Понятно, что сейчас есть много разных решений. Наверное, скажу только одну важную вещь, что сейчас, если вы используете MySQL или другие OLT базы данных, то имеет смысл использовать флаш ??, т.е. про диски, которые крутятся, забыли.
С точки зрения сети чаще всего производительность MySQL-сервера упирается во время отклика, а не в пропускную способность, особенно учитывая то, что люди часто делают достаточно много запросов в MySQL на каждую страницу. Часто это бывают сотни запросов, а в некоторых случаях я даже видел и десятки тысяч. Из этого вывод, что мы хотим, чтоб у нас было как можно лучше минимальное время отклика, значит, мы хотим, чтобы у нас MySQL-сервера и application-сервера говорили как можно больше напрямую. Чем меньше шагов сети (network hops), тем лучше. Размещать, например, application-сервер в одном месте, а базу данных в другом, в разных городах, на разных континентах – очень плохая идея, даже если вам говорят, что «а вот у нас лежит между ними свое «оптоволокно» на какие-то Гбиты». Потому скорость света – она конечная, и когда мы говорим о мк или долях мс, она уже начинает влиять правильно.
Выбор операционной системы. MySQL наиболее успешно используется на Linux. Кто-нибудь MySQL на чем-нибудь другом использует? FreeBSD, Windows server. Но большинство крупных проектов использует MySQL все-таки на Linux. В данном случае имеет смысл использовать серверный вариант этой ОС, который и оптимизирован для этого, и который не будет меняться каждые три месяца, и который нужно постоянно апгрейдить. И достаточно новый, особенно, если вы используете новое железо, потому что все, что касается флаш, то, что касается поддержки функциональности новых процессоров – это все поддерживается в более новых ядрах, новых дистрибутивах куда лучше, чем в старых.

Что интересно с точки зрения Linux. На самом деле, его дефолтные настройки для многих MySQL-нагрузок достаточно адекватны. Понятно, что если мы пойдем в какие-то там Google, Facebook – им важны последние 3-5% производительности, они инвестируют много в тюнинг ядра тоже или часто даже компилируют его специально, или патчат, но для большинства людей это не настолько важно. Файловая система – наиболее часто, мы видим, используется либо EXT4 либо XFS. На разных нагрузках либо одна, либо другая может
показывать лучшую производительность, но эти две файловые системы. И по ссылке я об этом поговорил более подробно.

Следующий момент – версия MySQL. Что нужно знать? Что новые версии MySQL обычно улучшают производительность. Есть исключения, т.е. если мы используем один поток клиентский и используем очень простые запросы, то на самом деле, поскольку MySQL становится более толстым, пытается делать больше оптимизации запросов, производительность на таких запросах может не существенно, но быть медленнее в новых версиях MySQL. На прошлой неделе вышел MySQL 5.7, что очень классно. Там очень много улучшений, как связанных с оптимайзером, так и с общей масштабируемостью, т.е. если вы хотите максимальной производительности MySQL, на него имеет смысл смотреть, но когда вы будете апгрейдиться, вы можете подождать Percona Server 5.7, который тоже выйдет через некоторое число месяцев.

MySQL-конфигурация. Здесь важно, что дефолты в MySQL-конфигурации плохие. Т.е. с дефолтами для MySQL работать нельзя. Но при этом тоже, не смотрите на него: «Елки-палки! Здесь есть 400 разных настроек». Вам, скорее всего, нужно будет исправить 5-10-20, для того, чтобы получить адекватную
производительность. Опять-таки, можете посмотреть мои слайды или вебинар с большими деталями по этому поводу.

Если вам лень туда смотреть, то можно взять эти настройки, ввести их в Google, и вы легко найдете ответы на то, во что их нужно поставить для вашей конфигурации.

Следующий момент – с точки зрения процесса.
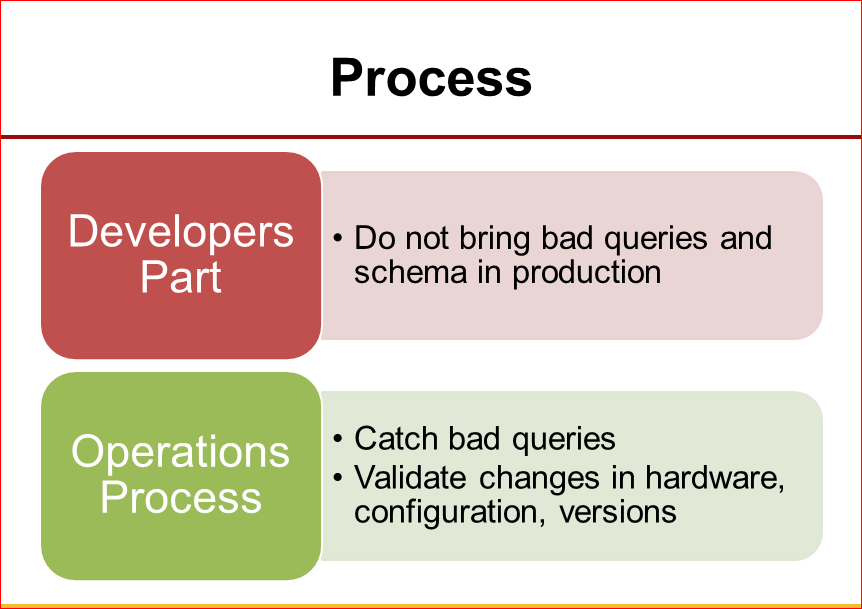
Есть две важные вещи:
- во-первых, нужно пасти разработчиков, потому что разработчики часто делают плохие запросы, которые, когда мы потом выкладываем код на продакшн, создают проблемы. Т.е. хорошо, если у нас есть процесс, когда мы кем-то, кто понимает базы данных, отслеживаем новые запросы, новые изменения схемы, которые предлагают разработчики. Это очень важная часть процесса.
- второй вопрос в том, что я никогда не видел, чтобы такой процесс предотвратил все проблемы, но и потому что разработчики, хотя и часто причина проблем с базами данных, но не всегда, иногда это бывает что-нибудь другое. Например, база данных сама в чем-нибудь виновата. Поэтому важно, чтобы уже на операционном уровне был какой-то процесс, чтоб ловить плохие запросы, отслеживать изменения версии MySQL в ОС, в конфигурации, также проверять всякие изменения железа, насколько оно хорошо работает. Очень-очень часто случается, что, например, мы пошли, купили железо, которое лучше, дороже, поставили его, а на самом деле оно работает медленнее, потому что мы там что-то не настроили, драйвер плохой, или Linux что-то еще не поддерживает. Доверяй, но проверяй, как говорится.

Следующий момент. Интересно, что со всеми этими настройками у нас, что бы мы ни изменили – железо, ОС, настройки MySQL – это всегда каким-то образом влияет на производительность запросов. Поэтому, если у вас есть какой-то мониторинг, что вы смотрите на производительность ваших запросов относительно времени, то вы всегда легко поймаете, если что-то вдруг стало плохо.

Значит, это вот тулзы, которые можно для этого использовать.

Я покажу один вариант, что мы сделали недавно. Это интеграция из MySQL performance Schema с Graphite.
Ссылка – http://bit.ly/1KQSNWC
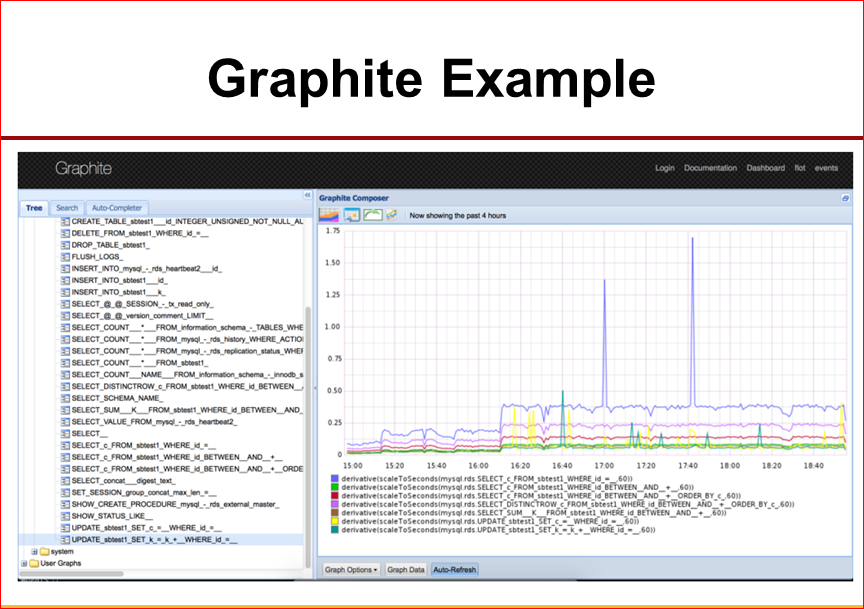
Здесь, вы видите, можно посмотреть суммарное время отклика для любого запроса MySQL, что очень полезно, потому что если начинает у нас что-то быть плохо, мы увидим, что у этого запроса съехал, например, план, теперь у нас занимает резко, в 10 раз больше суммарное время выполнения.
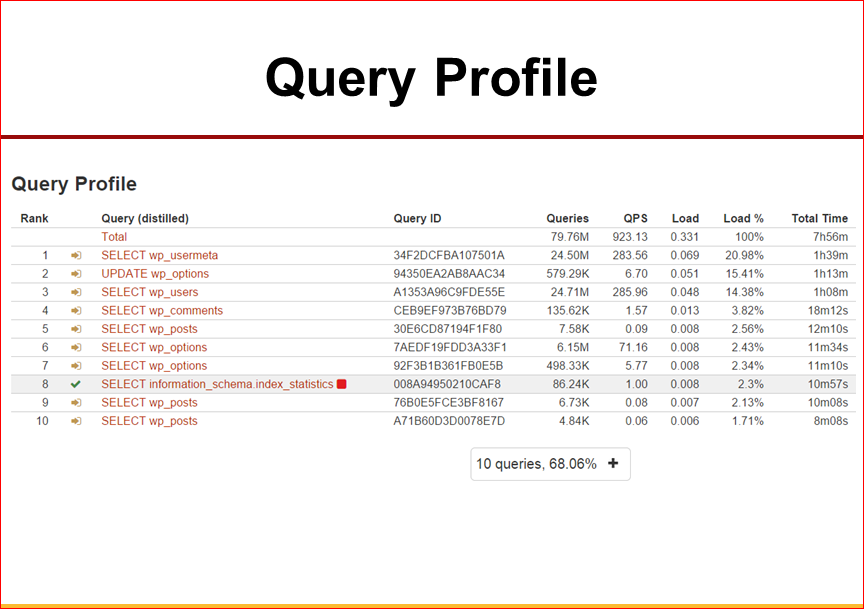
Это о том, что у нас важно. Смотрите за скоростью производительности приложения. И вот несколько хинтов, как их можно оптимизировать.


Ссылка – http://www.meetup.com/moscowmysql/

Ссылка – http://bit.ly/PL16Call
Контакты
» pz@percona.com
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++.
В рамках профессионального фестиваля "Российские интернет-технологии" мы проводим целую секцию по базам данных. Сейчас в ней 16 докладов, из которых нам надо выбрать 9. Вот, что мы уже точно выбрали:
Присоединяйтесь к нам!
- Postgres vs Mongo / Олег Бартунов (PostgreSQL Professional);
- Карты, деньги, два бэкапа: надежность данных / Николай Ихалайнен (Percona);
- Мониторинг и отладка MySQL: максимум информации при минимальных потерях / Света Смирнова (Percona);
- Обзор перспективных баз данных для highload / Юрий Насретдинов.
Смотри также:
- Курсоры в MySQL. Применение и синтаксис. Примеры. http://fetisovvs.blogspot.com/2016/10/mysql_13.html
- Представления (VIEW) в MySQL. http://fetisovvs.blogspot.com/2016/10/view-mysql.html
- Календарные функции в MySQL и MariaDB. http://fetisovvs.blogspot.com/2016/12/mysql-mariadb.html
- Как писать кривые запросы с неоптимальным планом и заставить задуматься СУБД. http://fetisovvs.blogspot.com/2017/02/blog-post_2.html
- Базовые различия при работе с базами данными MySQL и PostgreSQL Дилетантский обзор. http://fetisovvs.blogspot.com/2016/06/mysql-postgresql.html
- Сравнение производительности MariaDB 10.1 и MySQL 5.7. http://fetisovvs.blogspot.com/2015/10/mariadb-101-mysql-57.html
- MySQL и MongoDB — когда и что лучше использовать. http://fetisovvs.blogspot.com/2017/02/mysql-mongodb.html
- Балансировка MySQL. http://fetisovvs.blogspot.com/2015/08/mysql.html
- DbForge Studio for MySQL - удобный набор инструментов для профессиональной разработки и управления MySQL базы данных. http://fetisovvs.blogspot.com/2014/10/dbforge-studio-for-mysql-mysql.html
- Основы работы с DbForge Studio - инструментом для работы с MySQL. http://fetisovvs.blogspot.com/2014/11/dbforge-studio-mysql.html
- На пути к правильным SQL транзакциям. http://fetisovvs.blogspot.com/2015/06/sql.html
- Работа с PostgreSQL настройка и масштабирование (справочное пособие). http://fetisovvs.blogspot.com/2014/08/postgresql.html
- От Oracle к PostgreSQL – путь длиною в 4 года, доклад Андрея Рынкевича. http://fetisovvs.blogspot.com/2017/04/oracle-postgresql-4.html
- Электронная книга Инсталляция MySQL 5.5.24 http://fetisovvs.blogspot.com/2014/09/mysql-5524.html
- Зачем нужна денормализация баз данных, и когда ее использовать. http://fetisovvs.blogspot.com/2016/04/blog-post_10.html
- Как sql-запросом извлечь из базы данных информацию, которой там нет. http://fetisovvs.blogspot.com/2016/06/sql.html
- История СУБД Oracle — первой коммерчески успешной реляционной СУБД. http://fetisovvs.blogspot.com/2016/12/oracle.html
- NoSQL – коротко о главном. http://fetisovvs.blogspot.com/2017/01/nosql.htm
Комментариев нет:
Отправить комментарий